



Traditionelle Syntaxanalyse
07 Dec 2020 | Linguistik
- 1.Traditionelle Syntaxanalyse(전통적인 통사분석)
- 2.Satzanalyse(문장분석)
- 3.Syntaktische Tests(문법적 검사)
- 4.Syntaktische Kategorien und Funktionen(통사적 범주와 기능)
- 5.문장 분석을 위한 모델
- Reference
1.Traditionelle Syntaxanalyse(전통적인 통사분석)
Syntax(통사)
통사란 작은 단위(단어와 단어그룹)의 기본목록으로부터 완성된(문법적인) 문장이 형성되는 하나의 규범체계이다.
Akzeptabilitaet(수용가능성), Grammatikalitaet(문법성)
우리는 직감적으로 문장의 수용가능성과 문법성을 평가한다. 수용가능성(Akzeptabilitaet)은 Parle(언어사용) 층위와 관련 있는데, 문장이 의사소통에서 수용가능한지를 결정한다. 문법성(Grammtikalitaet)는 Langue(언어시스템) 층위와 관련되며, 문방이 규범체계를 통해 올바르게 형성됐는지를 결정한다.
Satz(문장)
문장의 정의에 대해서는 수많은 의견이 있다. 그 중 Gallman(2005)는 문장을 다음과 같이 정의했다:
- 문장은 하나의 정동사와 동사에 필요한 최소한의 Satzgliedern(문장구성요소들)로 이루어진 하나의 단위이다.
- 문장은 통사 규칙에 따라 형성된 독립된 단위이다.
- 문장은 통사 규칙으로 생성할 수 있는 가장 큰 단위이다.
2.Satzanalyse(문장분석)
문장 분석을 위한 방식과 문법형식은 목적에 따라 매우 다양하다.
2.1 Traditionelle Satzanalyse(전통적 문장분석 방식)
그 중 전통적인 시스템은 문장들의 형성 방식을 명확히 하기 위해 문장의 구조와 계층구조에 대해 연구한다. 이 방식은 주어가 Sonderstellung(특수한 지위)을 주어를 제외한 나머지는 다 술부로 취급한다. 다음은 기존 전통적 분석 방법으로 Der Professor haelt einen Vortrag을 분석한 것이다:

2.2 Dependenz-oder Valenzgrammatik(의존문법, 결합가문법)
의존문법 혹은 결합가문법은 각 문장의 구조적 중심이 정동사(finite Verb)라는 기본 개념을 기반으로 한다. 즉, 동사에 Sonderstellung이 있다고 가정한다. 따라서 Satzglieder(문장성분) 혹은 Konstituenten(구성요소)은 동사에 의해 결정된다. 다음은 위에서 사용된 예시 문장을 결합가문법으로 분석한 것이다:

2.3 Phrasenstrukturgrammtik(구구조문법)
Phrasenstrukturgrammtik(구구조문법)의 목적은 문장을 연구하여 문장구조와 계층을 명확히 할 뿐만 아니라 인간의 언어능력을 보편적으로 설명하고 언어 형식을 기술하는 것이다. 앞서 사용된 예시 문장을 생성변형문법의 초기 시스템에 따라 분석하면 다음과 같다:

3.Syntaktische Tests(문법적 검사)
문장을 어느 이론에 대입하더라도 중요한 것은 Satzglied(문장성분)이다. Satzglied란, 전체(뭉테기)로만 이동 혹은 대체가 가능한 문장의 가장 작은 요소(단어 혹은 단어그룹)이다. 즉, 문장은 단어들로 이루어져 있고 단어들은 서로 밀접한 관계를 맺은 Wortgrupp(단어그룹/구)을 형성하는데, 이런 단어와 단어 그룹을 Satzglied라고 한다. (예를 들어 이전에 사용하던 예시문에서 Der Professor과 einen Vortragdms Wortgrupp이지만 haelt einen은 밀접하게 결합된 관계가 아니기 때문에 Wortgrupp이 아니다.)
Satzglied는 VEA-Prinzip(VEA-원리)를 통해 식별될 수 있다. VEA-원리는 Verschiebung(교환)하고, Ersetzung(대체)하고, Anfansstellung(주제화)하는 것이다. 이제 Satzglieder 조사에 대한 일반적인 과정을 알아보겠다:
3.1 술어 찾기
3.2 교환(Verschiebeprobe/Permutation)
단일 단어그룹이나 단어들을 문장 내에서 Finitum(정동사)를 중심으로 옮겨지는데, 위치 이동 후에도 문장은 문법적이어야 한다. (정보와 문장정보(의문문, 명령문, 평서문 등)은 바뀌면 안된다.) 예를 들어:

3.3 대체(Ersetprobe/Substitution)
2번과정이 확실한 결과를 가져오지 못할 때(요소가 완전해서(geschlossen) 혹은 분리되어 옮겨져서) 이 과정을 통해 추가적으로 검증할 수 있다. 이 과정은 단어그룹이 한 단어를 통해(일반적으로 대명사) 대체될 수 있는지 검증하는 방법이다. 예를 들어 Im Korb lagen nur noch angefaulte Aepfel의 경우 2번 과정을 통해 Aepfel lagen nur noch angefaulte im Korb이 가능하다. 이 경우 문장구성요소목록(Satgliedinventar)이 im Korb – nur noch angefaulte – Aepfel로 파악된 것이다. 하지만 위 문장에서 angefaulte와 Aepfel은 동시에 움직여야 하며, 이는 대명사 sie로 대체될 수 있다.
3.4 주제화(Anfangsstellungsprobe/Topikalisierung)
단어그룹은 전장(Anfangsstellung, Vorfeldbesetzung)(정동사 앞)에 위치할 수 있다는 특성을 가진다. 따라서 이 과정에서는 전장에 위치할 수 있는지를 확인한다. 예를 들어 Nur noch angefaulte Aepfel은 이렇게 통으로 동사 앞에 올 수 있지만 Nur noch angefaulte만은 올 수 없다.
4.Syntaktische Kategorien und Funktionen(통사적 범주와 기능)
문장분석을 위해서는 통사적 요소(단어와 Satzglieder)가 결정되어야 한다. 즉, 각 단위들이 결정되어야 한다.
- 범주(Kategorie): X는 어떤 요소에 대한 것인가?
- 기능(Funktion): X는 문장 내에서 어떤 과제를 수행하는가?
4.1 Syntaktische Kategorien(통사적 범주)
통사적 범주에는 품사와 문장성분 분류(Satzgliedkategorie)가 속한다.
4.1-(1) 품사
품사란, 다양한 기준(형태론적, 통사론적, 의미론적 기준)을 통해 얻어진 범주로, 통사적 단어가 귀속될 수 있다. 즉, 한 단어에 세 가지 기준이 적용되어 품사가 결정된다.
1) Morphologische Kriterien(형태론적 기준)
우선 단어는 크게 굴절 가능한 단어와 그렇지 않은 단어로 나뉜다. 그리고 굴절 가능한 단어의 경우에는 동사형태변화(konjugieren), 강변화/약변화(deklinieren), 비교급변화(komparieren)을 통해 굴절될 수 있다. 여기에서 강변화/약변화가 가능한 단어(deklinierbaren Wort)는 성을 가지고 있는지에 따라 나뉠 수 있다. 이렇게 형태론적 기준의 적용을 통해 5가지 품사를 얻을 수 있다:

2) Syntaktische Kriterien(통사적 기준)
앞서 다룬 형태론적 기준에 문제가 있는데, 위 기준을 따르면 예를 들어 heut, vielleicht, weil, ueber, sehr가 다 Partikel이라는 같은 품사에 속하게 된다. 따라서 추가적으로 통사적 기준을 적용하여 품사를 구분해보고자 한다. 우선 굴절 불가능한 단어들 중 Satzglied 기능을 하는 단어들 (e.g. heute, vielleicht, deswegen)은 부사에 할당된다. 나머지 품사의 경우 통사적 관계를 설정하는 단어와 그렇지 않은 단어로 구분될 수 있다. 후자의 경우, (좁은 의미에서의) Partikeln으로 표기된다(e.g. das hast du ja toll hingekriegt에서 ja),즉 구체적인 paraphrasierbare(=umschreibbare)의미가 없는 단어이지만 대신 Abschwaechung(약화) 혹은 Verstaerkung(강조)와 같은 의사소통적 기능이 있는 단어. 반면 전자의 경우에는 통사적 관게에서 격이 요구(Praeposition, 예를 들어 nach+Dativ)되거나 Satzglieder 혹은 Teilsaetzen의 결합(Konjunktion(접속사), 예를 들어 und, weil)에 따라 나뉜다. 그리고 형태론적 기준에서 Begleiter로 분류되었던 부분도 Satzglieder기능을 하는지에 따라 나뉠 수 있다.

3) Semantische Kriterien(의미론적 기준)
지금까지 소개된 기준들을 통해 품사 구분이 어느정도 잘 되었지만 몇몇 문제점들이 있다. 예를 들어 oft라는 단어는 강약변화가 불가능하지만 비교급변화는 가능하다. 그리고 감탄사(Interjektion, e.g. ach!, oh!)와 문장과 대등한 표현(Satzaequivalente e.g. Ja, Danke)의 귀속도 모호하다. 따라서 단어의 품사는 문맥 속에서 결정된다. 이는 특히 여러 의미가 있는 단어들을 통해 확실해진다(e.g. natuerlich: 의미에 따라 형용사일 때도 있고 부사일 때도 있다). 반면 항상 같은 의미를 지닌 단어는 항상 같은 품사에 속한다. 예를 들어 schnell이라는 단어는 항상 형용사이다.

4.1-(1) 구(Phrasen=Wortgruppen)
이제 문장성분을 분류해보도록 하겠다. 단어 그룹 혹은 구에는 Phrasenkopf(혹은 Kern)이 있고, 그것의 품사를 통해 Phraes가 표기되는데, 이를 통해 단어 그룹의 유형이 결정된다.
Phrasenklassen

4.2 Syntaktische Funktionen(통사적 기능)
지금까지 통사적 범주에 대해 살펴보았다. 이제 통사적 기능에 대해 알아보도록 하겠다.
Syntaktische Funktionen von Wortgruppen(단어그룹의 통사적 기능)
문장에서 단어그룹은 특성 기능을 갖는다. (NP, VP 등으로 나뉘어도 통사적 기능을 따로 따져봐야 한다) 다음은 Christa Duerscheid가 제안한 통사적 기능에 대한 전형적인 목록이다.

범주와 기능으로 결정되어진 Satzglied는 다음과 같다:
Sie ist Aerztin, kuemmert sich gewissenhaft um die aegstlichen Patienten ihrer Landarztpraxis und muss sie immer ermutigen und ihnen die noetigen Rezepte ausstellen.
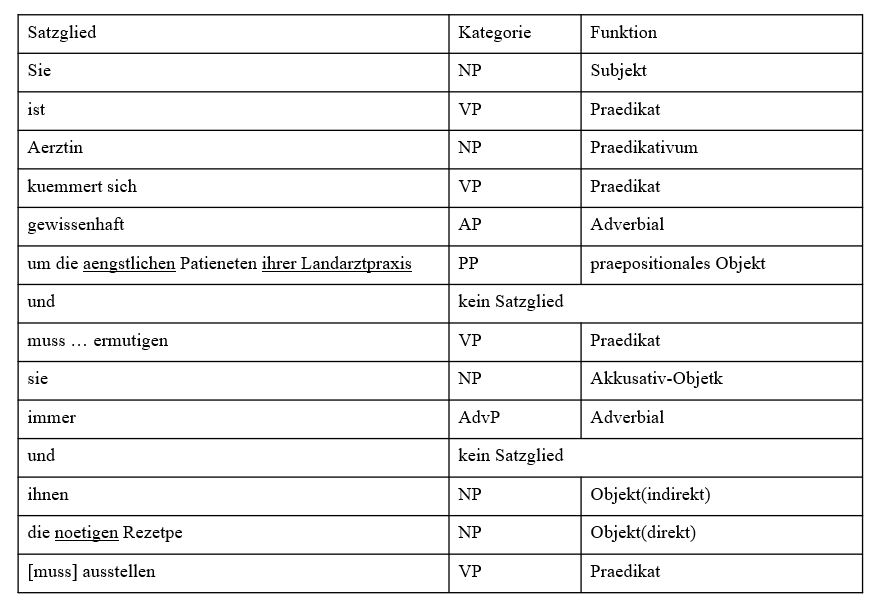
Attribute
위 표에서 밑줄 그어진 요소는 Attribute(부가어)인데, 이는 Satzglied가 아니라 Satzglied의 요소이다.
지금까지 전통적인 통사 분석에서 검증을 통해 문장을 그의 구성요소인 Satzglieder로 어떻게 나누고 이를 범주와 기능에 따라 더 면밀히 결정하는 방법에 대해 알아보았다. 이러한 전통적 문장성분분석을 요약하면 다음과 같다:

5.문장 분석을 위한 모델
이제 조금 더 복잡한 문장을 분석하기 위한 방법을 살펴보겠다.
5.1 Parataxe(중문)
중문은 동등한 주문장이 하나의 문장으로 연결된 것을 말한다. 두 주문장 사이의 접속사 유무로 중문의 유형이 나뉠 수 있다.
- Syndetische Verbindung(접속사로 연결된 중문): Die Geisteswissenschaften reflektieren seit jeher die kulturellen Grundlagen der Menschheit, und sie sichern mit ihren Herangehensweisen den gesellschaftlichen Zugriff auf kulturelle Inventare.
- Asyndetische Verbindung(접속사 없는 병렬): Die Geisteswissenschaften relfektieren seit jeher die kulturellen Grundlagen der Menschheit, sie sichern mit ihren Herangehensweisen den gesellschaftlichen Zugriff auf kulturelle Inventare.
5.2 Hypotaxe(주문장+부문장)
Hypotaxe는 주문장과 부문장이 결합하여 한 문장이 된 것으로, 복합분장 간의 서열과 단계가 있는 경우이다. 예를 들어:

- Matrixsatz
위 Hypotaxe는 6개의 부문장과 1개의 주문장으로 이루어져 있고, 서로 각각 종속된다. 종속된 부문장의 관점에서 볼 때 각 다음 상위문장을 Matrixsatz라고 한다. 즉, 각각 다음으로 높은 문장에 종속된 부분장의 관계를 나타낸 것으로, 예를 들어 Hauptsatz는 NS1의 Matrixsatz이다.
- Klassifikation von Nebensaetzen(부문장의 분류)
부문장은 세 가지 기준을 통해 분류될 수 있다:
1) 형식적(formal)으로 도입된 단어
2) 기능적(funktional)으로 Matrix안에서 차지할 수 있는 문장성분기능
3) 내용상으로 부사절인 경우
예를 들어:

이 뒤에 더 이어지면 그 부문장은 앞의 부분장에 대한 부가문장으로 온다:

4) Hauptsatzrest(주문장의 잔재)
주문장은 문장 성분들을 통해 보충되어진다. 예를 들어 Was ich nicht verstehen kann, ist, dass der Hauptsatz aus einem Wort besteht의 주문장은 술어 ist로만 이루어져 있다. 왜냐하면 주어와 술어가 부문장을 통해 보충되어지기 때문이다. 이렇게 축소된 주문장은 더 이상 문장이라고 말할 수 없기 때문에 주문장의 잔재(Hauptsatzrest/HSR)이라고 부른다.

지금까지 설명한 복잡한 문장에 대한 분석 스키마를 도식화하면 다음과 같다:

Reference
Albert Busch/Oliver Stenschke “Germanistische Linguistik: Eine Einführung,” Gunter Narr Verlag Tübingen. 2007
- 1.Traditionelle Syntaxanalyse(전통적인 통사분석)
- 2.Satzanalyse(문장분석)
- 3.Syntaktische Tests(문법적 검사)
- 4.Syntaktische Kategorien und Funktionen(통사적 범주와 기능)
- 5.문장 분석을 위한 모델
- Reference
1.Traditionelle Syntaxanalyse(전통적인 통사분석)
Syntax(통사)
통사란 작은 단위(단어와 단어그룹)의 기본목록으로부터 완성된(문법적인) 문장이 형성되는 하나의 규범체계이다.
Akzeptabilitaet(수용가능성), Grammatikalitaet(문법성)
우리는 직감적으로 문장의 수용가능성과 문법성을 평가한다. 수용가능성(Akzeptabilitaet)은 Parle(언어사용) 층위와 관련 있는데, 문장이 의사소통에서 수용가능한지를 결정한다. 문법성(Grammtikalitaet)는 Langue(언어시스템) 층위와 관련되며, 문방이 규범체계를 통해 올바르게 형성됐는지를 결정한다.
Satz(문장)
문장의 정의에 대해서는 수많은 의견이 있다. 그 중 Gallman(2005)는 문장을 다음과 같이 정의했다:
- 문장은 하나의 정동사와 동사에 필요한 최소한의 Satzgliedern(문장구성요소들)로 이루어진 하나의 단위이다.
- 문장은 통사 규칙에 따라 형성된 독립된 단위이다.
- 문장은 통사 규칙으로 생성할 수 있는 가장 큰 단위이다.
2.Satzanalyse(문장분석)
문장 분석을 위한 방식과 문법형식은 목적에 따라 매우 다양하다.
2.1 Traditionelle Satzanalyse(전통적 문장분석 방식)
그 중 전통적인 시스템은 문장들의 형성 방식을 명확히 하기 위해 문장의 구조와 계층구조에 대해 연구한다. 이 방식은 주어가 Sonderstellung(특수한 지위)을 주어를 제외한 나머지는 다 술부로 취급한다. 다음은 기존 전통적 분석 방법으로 Der Professor haelt einen Vortrag을 분석한 것이다:
2.2 Dependenz-oder Valenzgrammatik(의존문법, 결합가문법)
의존문법 혹은 결합가문법은 각 문장의 구조적 중심이 정동사(finite Verb)라는 기본 개념을 기반으로 한다. 즉, 동사에 Sonderstellung이 있다고 가정한다. 따라서 Satzglieder(문장성분) 혹은 Konstituenten(구성요소)은 동사에 의해 결정된다. 다음은 위에서 사용된 예시 문장을 결합가문법으로 분석한 것이다:
2.3 Phrasenstrukturgrammtik(구구조문법)
Phrasenstrukturgrammtik(구구조문법)의 목적은 문장을 연구하여 문장구조와 계층을 명확히 할 뿐만 아니라 인간의 언어능력을 보편적으로 설명하고 언어 형식을 기술하는 것이다. 앞서 사용된 예시 문장을 생성변형문법의 초기 시스템에 따라 분석하면 다음과 같다:
3.Syntaktische Tests(문법적 검사)
문장을 어느 이론에 대입하더라도 중요한 것은 Satzglied(문장성분)이다. Satzglied란, 전체(뭉테기)로만 이동 혹은 대체가 가능한 문장의 가장 작은 요소(단어 혹은 단어그룹)이다. 즉, 문장은 단어들로 이루어져 있고 단어들은 서로 밀접한 관계를 맺은 Wortgrupp(단어그룹/구)을 형성하는데, 이런 단어와 단어 그룹을 Satzglied라고 한다. (예를 들어 이전에 사용하던 예시문에서 Der Professor과 einen Vortragdms Wortgrupp이지만 haelt einen은 밀접하게 결합된 관계가 아니기 때문에 Wortgrupp이 아니다.)
Satzglied는 VEA-Prinzip(VEA-원리)를 통해 식별될 수 있다. VEA-원리는 Verschiebung(교환)하고, Ersetzung(대체)하고, Anfansstellung(주제화)하는 것이다. 이제 Satzglieder 조사에 대한 일반적인 과정을 알아보겠다:
3.1 술어 찾기
3.2 교환(Verschiebeprobe/Permutation)
단일 단어그룹이나 단어들을 문장 내에서 Finitum(정동사)를 중심으로 옮겨지는데, 위치 이동 후에도 문장은 문법적이어야 한다. (정보와 문장정보(의문문, 명령문, 평서문 등)은 바뀌면 안된다.) 예를 들어:
3.3 대체(Ersetprobe/Substitution)
2번과정이 확실한 결과를 가져오지 못할 때(요소가 완전해서(geschlossen) 혹은 분리되어 옮겨져서) 이 과정을 통해 추가적으로 검증할 수 있다. 이 과정은 단어그룹이 한 단어를 통해(일반적으로 대명사) 대체될 수 있는지 검증하는 방법이다. 예를 들어 Im Korb lagen nur noch angefaulte Aepfel의 경우 2번 과정을 통해 Aepfel lagen nur noch angefaulte im Korb이 가능하다. 이 경우 문장구성요소목록(Satgliedinventar)이 im Korb – nur noch angefaulte – Aepfel로 파악된 것이다. 하지만 위 문장에서 angefaulte와 Aepfel은 동시에 움직여야 하며, 이는 대명사 sie로 대체될 수 있다.
3.4 주제화(Anfangsstellungsprobe/Topikalisierung)
단어그룹은 전장(Anfangsstellung, Vorfeldbesetzung)(정동사 앞)에 위치할 수 있다는 특성을 가진다. 따라서 이 과정에서는 전장에 위치할 수 있는지를 확인한다. 예를 들어 Nur noch angefaulte Aepfel은 이렇게 통으로 동사 앞에 올 수 있지만 Nur noch angefaulte만은 올 수 없다.
4.Syntaktische Kategorien und Funktionen(통사적 범주와 기능)
문장분석을 위해서는 통사적 요소(단어와 Satzglieder)가 결정되어야 한다. 즉, 각 단위들이 결정되어야 한다.
- 범주(Kategorie): X는 어떤 요소에 대한 것인가?
- 기능(Funktion): X는 문장 내에서 어떤 과제를 수행하는가?
4.1 Syntaktische Kategorien(통사적 범주)
통사적 범주에는 품사와 문장성분 분류(Satzgliedkategorie)가 속한다.
4.1-(1) 품사
품사란, 다양한 기준(형태론적, 통사론적, 의미론적 기준)을 통해 얻어진 범주로, 통사적 단어가 귀속될 수 있다. 즉, 한 단어에 세 가지 기준이 적용되어 품사가 결정된다.
1) Morphologische Kriterien(형태론적 기준)
우선 단어는 크게 굴절 가능한 단어와 그렇지 않은 단어로 나뉜다. 그리고 굴절 가능한 단어의 경우에는 동사형태변화(konjugieren), 강변화/약변화(deklinieren), 비교급변화(komparieren)을 통해 굴절될 수 있다. 여기에서 강변화/약변화가 가능한 단어(deklinierbaren Wort)는 성을 가지고 있는지에 따라 나뉠 수 있다. 이렇게 형태론적 기준의 적용을 통해 5가지 품사를 얻을 수 있다:
2) Syntaktische Kriterien(통사적 기준)
앞서 다룬 형태론적 기준에 문제가 있는데, 위 기준을 따르면 예를 들어 heut, vielleicht, weil, ueber, sehr가 다 Partikel이라는 같은 품사에 속하게 된다. 따라서 추가적으로 통사적 기준을 적용하여 품사를 구분해보고자 한다. 우선 굴절 불가능한 단어들 중 Satzglied 기능을 하는 단어들 (e.g. heute, vielleicht, deswegen)은 부사에 할당된다. 나머지 품사의 경우 통사적 관계를 설정하는 단어와 그렇지 않은 단어로 구분될 수 있다. 후자의 경우, (좁은 의미에서의) Partikeln으로 표기된다(e.g. das hast du ja toll hingekriegt에서 ja),즉 구체적인 paraphrasierbare(=umschreibbare)의미가 없는 단어이지만 대신 Abschwaechung(약화) 혹은 Verstaerkung(강조)와 같은 의사소통적 기능이 있는 단어. 반면 전자의 경우에는 통사적 관게에서 격이 요구(Praeposition, 예를 들어 nach+Dativ)되거나 Satzglieder 혹은 Teilsaetzen의 결합(Konjunktion(접속사), 예를 들어 und, weil)에 따라 나뉜다. 그리고 형태론적 기준에서 Begleiter로 분류되었던 부분도 Satzglieder기능을 하는지에 따라 나뉠 수 있다.
3) Semantische Kriterien(의미론적 기준)
지금까지 소개된 기준들을 통해 품사 구분이 어느정도 잘 되었지만 몇몇 문제점들이 있다. 예를 들어 oft라는 단어는 강약변화가 불가능하지만 비교급변화는 가능하다. 그리고 감탄사(Interjektion, e.g. ach!, oh!)와 문장과 대등한 표현(Satzaequivalente e.g. Ja, Danke)의 귀속도 모호하다. 따라서 단어의 품사는 문맥 속에서 결정된다. 이는 특히 여러 의미가 있는 단어들을 통해 확실해진다(e.g. natuerlich: 의미에 따라 형용사일 때도 있고 부사일 때도 있다). 반면 항상 같은 의미를 지닌 단어는 항상 같은 품사에 속한다. 예를 들어 schnell이라는 단어는 항상 형용사이다.
4.1-(1) 구(Phrasen=Wortgruppen)
이제 문장성분을 분류해보도록 하겠다. 단어 그룹 혹은 구에는 Phrasenkopf(혹은 Kern)이 있고, 그것의 품사를 통해 Phraes가 표기되는데, 이를 통해 단어 그룹의 유형이 결정된다.
Phrasenklassen
4.2 Syntaktische Funktionen(통사적 기능)
지금까지 통사적 범주에 대해 살펴보았다. 이제 통사적 기능에 대해 알아보도록 하겠다.
Syntaktische Funktionen von Wortgruppen(단어그룹의 통사적 기능)
문장에서 단어그룹은 특성 기능을 갖는다. (NP, VP 등으로 나뉘어도 통사적 기능을 따로 따져봐야 한다) 다음은 Christa Duerscheid가 제안한 통사적 기능에 대한 전형적인 목록이다.
범주와 기능으로 결정되어진 Satzglied는 다음과 같다:
Sie ist Aerztin, kuemmert sich gewissenhaft um die aegstlichen Patienten ihrer Landarztpraxis und muss sie immer ermutigen und ihnen die noetigen Rezepte ausstellen.
Attribute
위 표에서 밑줄 그어진 요소는 Attribute(부가어)인데, 이는 Satzglied가 아니라 Satzglied의 요소이다.
지금까지 전통적인 통사 분석에서 검증을 통해 문장을 그의 구성요소인 Satzglieder로 어떻게 나누고 이를 범주와 기능에 따라 더 면밀히 결정하는 방법에 대해 알아보았다. 이러한 전통적 문장성분분석을 요약하면 다음과 같다:
5.문장 분석을 위한 모델
이제 조금 더 복잡한 문장을 분석하기 위한 방법을 살펴보겠다.
5.1 Parataxe(중문)
중문은 동등한 주문장이 하나의 문장으로 연결된 것을 말한다. 두 주문장 사이의 접속사 유무로 중문의 유형이 나뉠 수 있다.
- Syndetische Verbindung(접속사로 연결된 중문): Die Geisteswissenschaften reflektieren seit jeher die kulturellen Grundlagen der Menschheit, und sie sichern mit ihren Herangehensweisen den gesellschaftlichen Zugriff auf kulturelle Inventare.
- Asyndetische Verbindung(접속사 없는 병렬): Die Geisteswissenschaften relfektieren seit jeher die kulturellen Grundlagen der Menschheit, sie sichern mit ihren Herangehensweisen den gesellschaftlichen Zugriff auf kulturelle Inventare.
5.2 Hypotaxe(주문장+부문장)
Hypotaxe는 주문장과 부문장이 결합하여 한 문장이 된 것으로, 복합분장 간의 서열과 단계가 있는 경우이다. 예를 들어:
- Matrixsatz
위 Hypotaxe는 6개의 부문장과 1개의 주문장으로 이루어져 있고, 서로 각각 종속된다. 종속된 부문장의 관점에서 볼 때 각 다음 상위문장을 Matrixsatz라고 한다. 즉, 각각 다음으로 높은 문장에 종속된 부분장의 관계를 나타낸 것으로, 예를 들어 Hauptsatz는 NS1의 Matrixsatz이다.
- Klassifikation von Nebensaetzen(부문장의 분류)
부문장은 세 가지 기준을 통해 분류될 수 있다:
1) 형식적(formal)으로 도입된 단어
2) 기능적(funktional)으로 Matrix안에서 차지할 수 있는 문장성분기능
3) 내용상으로 부사절인 경우
예를 들어:
이 뒤에 더 이어지면 그 부문장은 앞의 부분장에 대한 부가문장으로 온다:
4) Hauptsatzrest(주문장의 잔재)
주문장은 문장 성분들을 통해 보충되어진다. 예를 들어 Was ich nicht verstehen kann, ist, dass der Hauptsatz aus einem Wort besteht의 주문장은 술어 ist로만 이루어져 있다. 왜냐하면 주어와 술어가 부문장을 통해 보충되어지기 때문이다. 이렇게 축소된 주문장은 더 이상 문장이라고 말할 수 없기 때문에 주문장의 잔재(Hauptsatzrest/HSR)이라고 부른다.
지금까지 설명한 복잡한 문장에 대한 분석 스키마를 도식화하면 다음과 같다:
Reference
Albert Busch/Oliver Stenschke “Germanistische Linguistik: Eine Einführung,” Gunter Narr Verlag Tübingen. 2007