



Assessing the ability of Transformer-based Neural Models to represent structurally unbounded dependencies(Da Costa.J et al.(2020))
04 Apr 2021 | NLP & Linguistics
- 1. Introduction
- 2. LSTM RNNs
- 3. Transformer-XL
- 3.1 Experiment 1, 2 result: agreement in clefts, agreement in indirect interrogatives
- 3.2 Experiment 3: Filler-gap surprisal in subject-inverted interrogatives
- 3.2.1 Experiment 3 result: Filler-gap surprisal in subject-inverted interrogatives
- 3.3 Experiment 4: Filler-gap surprisal in uninverted indirect interrogatives
- 3.3.1 Experiment 4 result: Filler-gap surprisal in uninverted indirect interrogatives
- 4. BERT
- 4.1 Experiment 1 result: agreement in clefts
- 4.2 Experiment 2 result: agreement in indirect interrogatives
- 4.3 Additional Experiment 1 result
- 4.4 Experiment 3, 4 result: Filler-gap surprisal in subject-inverted interrogatives, Filler-gap surprisal in uninverted indirect interrogatives
- 4.5 Additional Experiment 2 result
- 5. XLNet
- 6. GPT-2
- 7. Discussion
- Reference
1. Introduction
본 연구에서는 영어의 장거리 의존문장을 여러 학습 모델에서 어떻게 처리하는지에 대해 실험한다. 장거리 의존 구문이란 자연어가 가지고 있는 sequential 한 속성과 더불어 hierarchical한 속성을 가지고 있다는 대표적인 예시이다. 영어에서 나타나는 대표적인 장거리 의존 구문은 WH-question, Relative clause, Topicalization이다. 장거리 의존 구문에 대한 자세한 설명은 Long-Distance Dependency 여기에 있다.
장거리 의존 문장과 같이 복잡한 구조를 가진 문장을 잘 파악하지 못하면 아래와 같은 오류를 낼 수 있기 때문에 자연어처리 분야에서의 장거리 의존 구문 처리는 매우 중요하다.
It was the lawyer(s) who I think you said (GAP) was/were upset.
-> It was the lawyer who I think you said (GAP) was/*were upset.
-> It was the lawyer(s) who I think you said (GAP) *was/were upset.
따라서 본 연구에서는 딥러닝 모델들이 다양한 형태의 장거리 의존 구문을 잘 처리하는지 알아보고자 한다.
2. LSTM RNNs
여기에서 사용되는 모델은 Gulordava model과 Google model이다. Gulordava model은 English Wikipedia corpus 9000만 token으로 학습되었고 650 unit hidden layer 두 개를 가진다. Google model은 10억개의 Word Benchmark(Chelba et al., 2013)로 학습되었고 8196 unit을 가진 두 개의 hidden layer로 이루어져 있다. 그리고 character level CNN의 output을 LSTM의 input으로 사용한다. 이 두 모델은 아래와 같은 두 가지 조건 하에 사용된다. 기본적인 실험 방식은 Wilcox et al.(2019b)를 기반으로 한다.
2.1 Experiment 1: agreement in clefts
첫 번째 조건은 cleft sentence(분열문)이다. 분열문은 한 문장이 두 부분으로 구성되어 있는 문장으로, it-that 강조구문을 생각하면 쉽다.

위 예문 a는 wh-관계절로 이루어진 문장으로, it was the lawyer부분과 삽입절 I think로 나뉠 수 있다. 위 예문 a, b, c, d는 순서대로 삽입절의 개수가 점점 추가되는 것을 확인할 수 있다. 이에 따라 내포 수준(LEVEL)도 증가하는 것도 볼 수 있다.
본 실험에서는 2x2x4 factorial design(삽입절을 통해 강조되는 the lawyer(s)는 단수일 경우와 복수일 경우가 존재하며 이에 따라 동사의 경우도 2가지(단수/복수), 위 예문처럼 삽입절이 추가되는 4가지 문장)을 이용한 20 cleft item을 만들어 총 320문장을 가지고 실험을 진행한다.
2.2 Experiment 2: agreement in indirect interrogatives
두 번째 조건은 indirect interrogative(간접의문문)이다. 이는 embedded question이라고도 하는데, 종속절로 기능하는 의문문이다.

여기에서도 마찬가지로 2x2x4 factorial design, 20 cleft items, 320 sentences로 실험이 진행된다.
2.3 Result
두 조건에 대한 결과는 Surprisal로 제시된다. 본 실험에서는 수일치를 확인하고자 하기 때문에 RNN이 수일치에 성공했다면 Surprisal 수치가 낮을 것이고 틀렸다면 높을 것이다.
Surprisal(의외성/놀람)
Wilcox et al. (2018)에서는 log inverse probability라고 하며 아래와 같은 공식을 제시하였다.
위 수식에서 x_i는 예측하고자 하는 단어이고 h_{i-1}은 x_i 이전의 hidden state 값이다. 따라서 맢선 맥락을 바탕으로 해당 단어에 대해 기대하는 정도를 surprisal로 나타낸다. 값이 낮을수록 의외가 아닌 것이고 높을수록 의외인 것이다.
(공식)
CoNLL에서 주로 사용되는 개념으로, Surprisal(의외성)은 사건이 일어나지 말아야하는 환경에서 나타날 경우에 나타나는 놀라움의 정도를 나타낸다. 예를 들어 초등학교 동창을 같은 동네에서 마주친 것보다 휴가지로 떠난 하와이에서 마주친 경우가 의외성의 수준이 더 높은 것이다.
2.3.1 Experiment 1 result: agreement in clefts
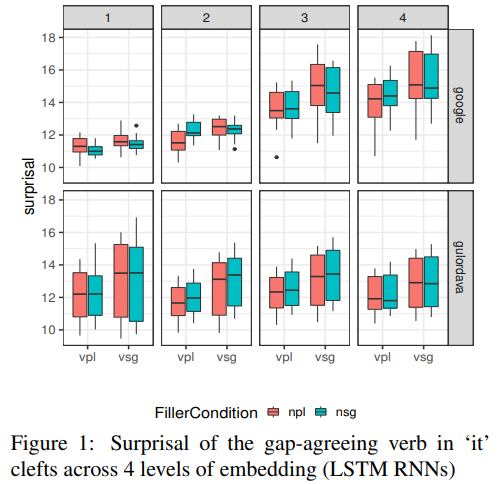
위 표에서 npl(빨간 박스)은 복수명사, nsg(초록 박스)는 단수명사를 나타낸다. 그리고 표의 x축에는 vpl(복수 동사)와 vsg(단수동사)가 나와있고 위에 제시된 숫자는 삽입절 내포 수준을 나타낸다. RNN이 제대로 학습했다면 명사가 복수일 때 동사가 복수여야 하기 때문에 초록색 박스보다 빨간색 박스의 수치가 낮게 나타나야 한다. 하지만 표를 보면 두 박스가 나타내는 수치의 차이가 거의 없다. google model에서는 삽입절이 많을수록 surprisal값이 높아지는 것을 볼 수 있다(예측을 잘 하지 못한다).
2.3.2 Experiment 2 result: agreement in indirect interrogatives
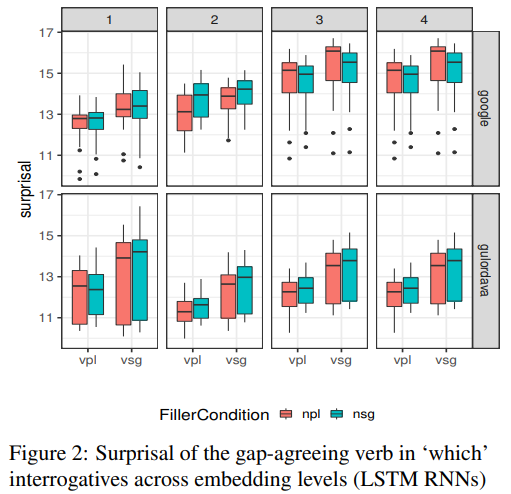
두 번째 실험의 결과도 첫 번째 실험처럼 전반적으로 겹침이 많은 것을 볼 수 있다. 따라서 Gulordava와 Google model은 장거리 의존 구문의 형태 통사적인 특징을 잘 학습하지 못한다는 것을 알 수 있다.
3. Transformer-XL
Transformer-XL은 기존 Transformer의 self-attention network에 ‘recurrence’개념을 도입한 모델이다. 기존 Transformer는 현재의 정보를 처리할 때 이전 정보가 단절되는데 Transformer-XL은 recurrence를 도입하여 이전 정보가 현재 정보에도 전파되도록 한다. Dai et al.(2019)에 따르면 RNN보다 80%더 긴 dependency를 학습할 수 있다고 한다. 이를 증명하기 위해 본 논문에서는 RNN으로 진행한 실험을 동일하게 진행하였다.
3.1 Experiment 1, 2 result: agreement in clefts, agreement in indirect interrogatives
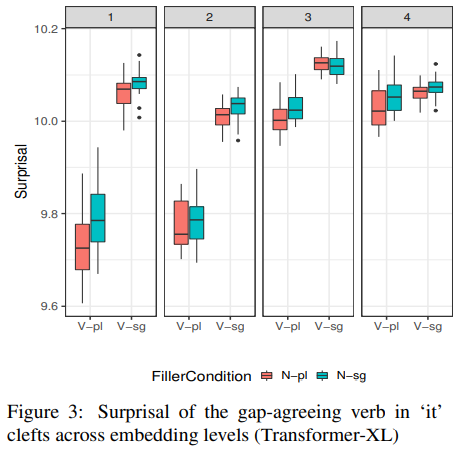
위 그래프는 실험 1의 결과를 시각화한 것이다. 내포수준 1과 3에서만 주-동 수 일치 surprisal이 불일치 surprisal보다 낮게 나왔다. 즉 내포수준 1과 3에서만 제대로 구분을 하고 나머지는 못하는 것이다. 따라서 Transformer-XL의 성능이 RNN보다 아주 조금 더 좋다는 것을 알 수 있다.
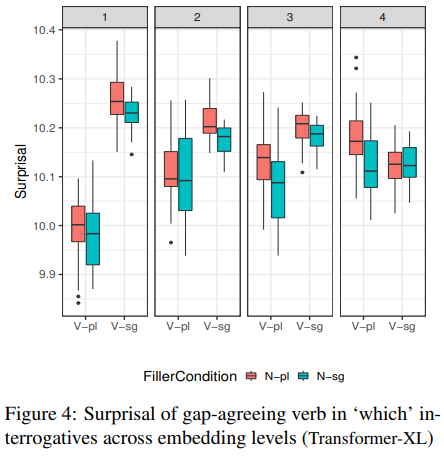
실험 2에서도 결과가 좋지 않았다.
3.2 Experiment 3: Filler-gap surprisal in subject-inverted interrogatives
실험3은 주어가 도치된 의문문의 dependency에 대한 실험이다. 아래 예시 문장의 경우, talk about의 목적어가 what으로 대체되고 what이 절의 맨앞으로 이동한 것이다. 이때 what이 원래 있던 자리에 GAP이 생기는데 이 GAP과 what 사이에 dependency가 발생한다. GAP자리에 목적어 it을 삽입하면 talk about의 목적어가 두개(what과 it)가 되어버리기 때문에 비문이 된다. 따라서 실험3은 what과 GAP사이의 dependency를 모델이 잘 처리할 수 있는지 알아보는 것이다.

20개의 item 대해 WH-question이 있는 문장과 없는 문장 그리고 GAP이 있는 것과 없는 것 그리고 내포수준 1-4까지 해서 20x2x2x4, 총 320문장으로 실험을 진행한다.
그리고 GAP뒤에 나오는 item, 위 예시에서는 at뒤에 나오는 item의 softmax값(확률값)을 추출한다.
본 논문의 저자인 Rui P. Chaves는 island effect를 전공한 사람이다. 그래서 experiment syntax 연구 모델을 활용하여 본 실험을 설계한 것이다. a, b, c, d에서 b와 c는 정문이고 a와 d는 비문이다. 이와 같은 2x2 design은 a-b, a-c, c-d 각각이 syntactic constraint를 기준으로 하나의 minimal pair가 된다. 이런 식으로 2x2 conditional design으로 정석적인 experiment syntactic method를 사용하였다. 20개의 item은 각 항목마다 lexicalization을 해서 20개씩 분포했다는 말이다. 이러한 metric은 human evaluation에서도 매우 좋은 설계이다.
3.2.1 Experiment 3 result: Filler-gap surprisal in subject-inverted interrogatives
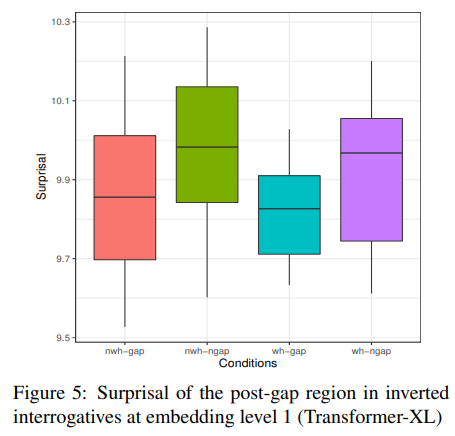
위 boxplot은 내포수준 1에 대한 결과를 시각화 한 것이다. 그래프 상에서 두 번째와 세 번째 박스가 정문이고 첫 번째와 네 번째 박스가 비문에 해당한다(wh가 없을 때는 gap도 없어야 정문이고 wh가 있을 때는 gap도 있어야 정문이 된다.) 따라서 모델이 예측을 잘 했다면 두 번째와 세 번째 surprisal이 첫 번째와 네 번째보다 낮아야 한다. 하지만 실험 결과, 정문에 해당하는 surprisal이 비문에 해당하는 surprisal보다 높게 나타났다. 나머지 내포수준에서도 전반적으로 결과가 좋지 않아 Transformer-XL이 주어 도치 의문문 처리 성능이 좋지 않음이 확인되었다.
최근 정략적 기반의 empirical linguistic study에서 boxplot을 이용한 시각화가 많이 보이고 있다.
3.3 Experiment 4: Filler-gap surprisal in uninverted indirect interrogatives

실험 4에서는 모델이 도치가 안 된 간접 의문문에서의 dependency를 파악할 수 있는지를 확인한다. 일반적으로 의문문은 주어와 동사가 도치되지만 의문문이 모절 안에 내포될 경우에는 도치 없이 실현된다. What과 GAP사이에 dependency가 발생한다는 점은 실험 3과 동일하지만 We talked about과 같이 주어와 동사가 도치되지 않는 점이 차이이다.
3.3.1 Experiment 4 result: Filler-gap surprisal in uninverted indirect interrogatives
실험 4의 결과는 그냥 처참하다. 모든 embedding level에서 올바른 surprisal pattern이 관찰되지 않았다. Transformer-XL은 RNN보다 dependency처리 능력이 나쁘다고 볼 수 있다.
4. BERT
BERT에 대한 자세한 설명은 BERT여기에 있다.
4.1 Experiment 1 result: agreement in clefts
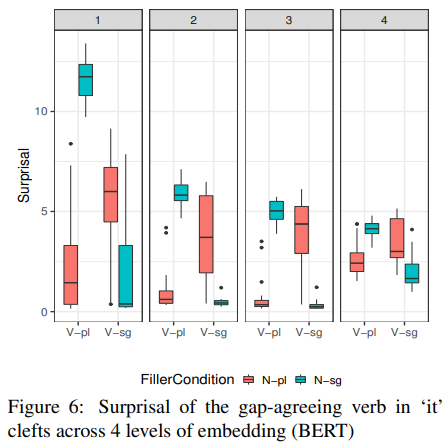
BERT에는 masked token이 사용되는데 본 실험에서는 be동사에 masking을 했다.
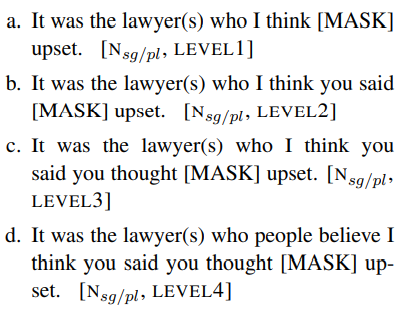
위 예문처럼 was나 were부분을 가려놓고 그 곳의 surprisal값을 구하는 방식으로 실험을 진행하였다. 정문이 비문보다 surprisal이 낮아야 한다. 위 boxplot을 보면 한 박스 내에서 1번과 4번이 낮고 2번과 3번이 높게 나타나 BERT 실험 결과가 통계적으로 유효한 차이를 보이고 있음을 알 수 있다.
4.2 Experiment 2 result: agreement in indirect interrogatives
실험 2는 간접 의문문과 관련된 실험이다.
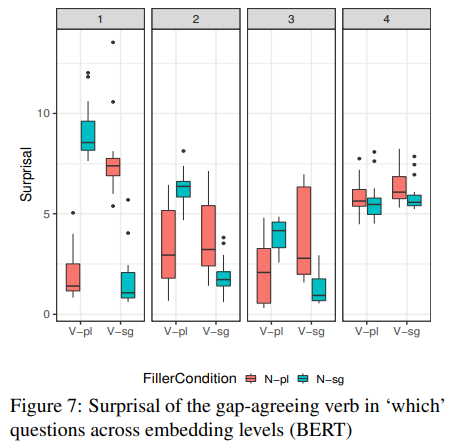
여기에서도 실험 1과 마찬가지로 한 박스 내에서 1번과 4번이 나머지보다 surprisal이 낮아야 한다. 내포수준 1, 2, 3에서는 잘 처리가 되고 있고 level4에서는 조금 결과가 안 좋다. 조금 아쉬운 결과지만 다른 모델들보다 BERT의 결과가 가장 잘 나왔다.
4.3 Additional Experiment 1 result
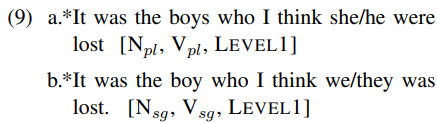
위 실험 결과와 같이 BERT가 언어를 잘 처리한다는 결과가 나왔는데 정말로 잘 처리하는 것인가를 알아보기 위해 추가적인 실험을 진행하였다. long-distance dependency처럼 생겼지만 long-distance dependency를 처리하는 것처럼 처리하면 안 되는 경우에 BERT가 어떤 반응을 보이는지 살펴보았다. 예를 들어 앞에 나온 NP와 뒤에 나오는 동사의 수가 다른 조건을 주어 헷갈리게 하는 것이다.
위 예문을 보면 동사는 the boy/the boys가 아닌 she/he와 we/they에 걸려야 정문이 되는 문장인데 동사가 the boy/the boys에 걸려서 비문이 되었다.
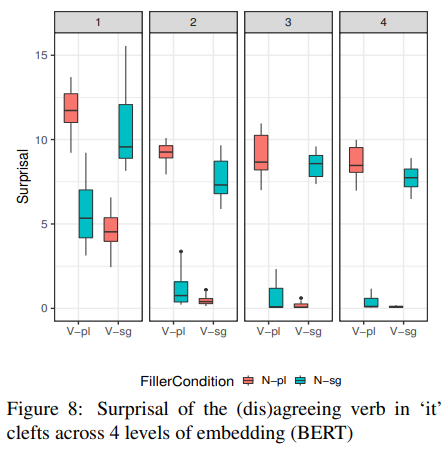
위 그래프는 이 실험에 대한 결과이다. 본 실험은 앞에 있는 NP와 동사의 단복수가 다른 조건에서 surprisal이 낮아야 하는 상황이기 때문에 다른 실험들의 결과와는 반대로 나타나야 한다. 위 그래프를 보면 BERT가 문장을 잘 파악해서 주-동 수일치를 잘 식별한 것을 알 수 있다.
4.4 Experiment 3, 4 result: Filler-gap surprisal in subject-inverted interrogatives, Filler-gap surprisal in uninverted indirect interrogatives
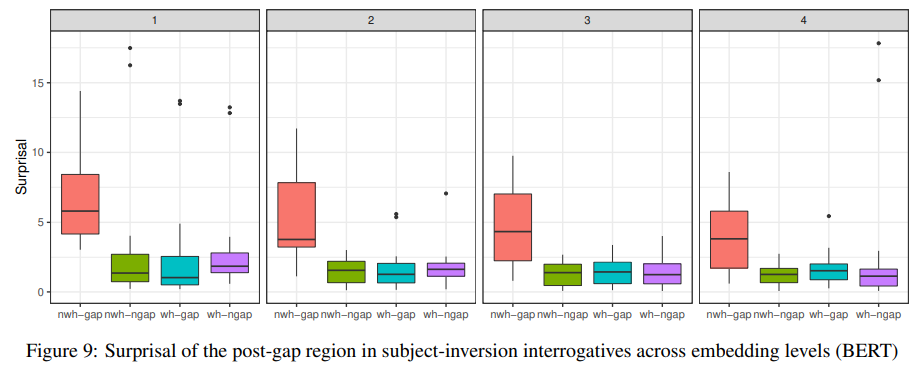
이 실험은 앞선 실험과는 달리 long distance dependency를 도치와 비도치 의문문 조건에서 살펴본다.
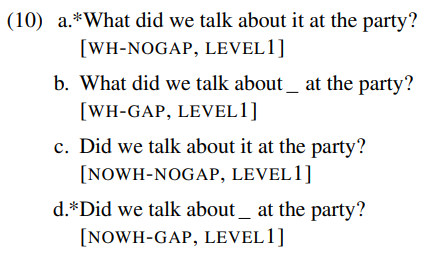

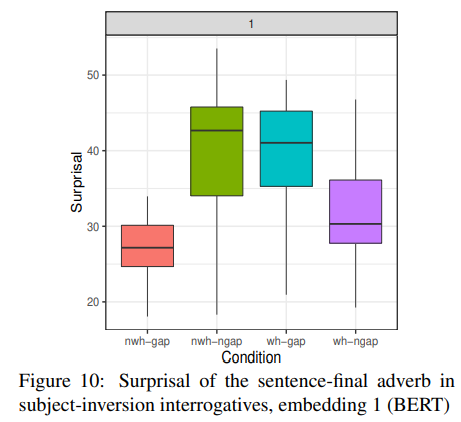
10번과 11번 예문을 보면 뒤에 있는 at the party에서 at을 masking 해놓고 이것의 softmax값을 도출하면서 surprisal값을 낸다. 정문인 경우 at이 있어야 하기 때문에 surprisal이 낮게 나타날 것이고 비문의 경우에는 at이 있으면 이상하니까 surprisal이 높을 것이다. 정문인 b와 c는 boxplot에서 2번과 3번에 대응되기 때문에 2번과 3번은 낮아야 하고 1번과 4번이 높게 나와야 하는데 잘 처리되고 있음을 볼 수 있다.
4.5 Additional Experiment 2 result
BERT가 우수한 성과를 내는 이유 중 하나는 양방향 학습이라고 볼 수 있다. 양방향으로 학습하며 후행 성분을 고려하는 특성으로, 앞선 다른 모델들에 대한 실험과 골자는 동일하지만 critical item에 yesterday repeatedly, again, then과 같은 부사를 넣어 실험을 진행한다.
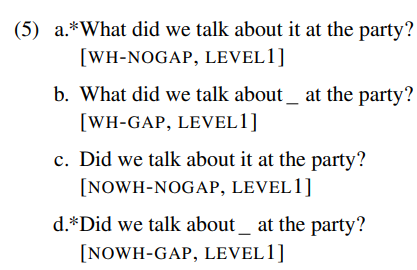
(12)b,c는 정문이고 a, d는 비문이다.
위 boxplot에서 두 번째와 세 번째가 b와 c에 대응하고 첫 번째와 네 번째는 a와 d에 대응한다. 위 표를 보면 정문이 비문보다 낮게 나타나야 하는데 지금까지 진행한 BERT실험들과는 좋지 않은 결과가 나왔다. 이는 BERT의 처리 능력에도 한계가 있다는 것을 시사한다.
5. XLNet
XLNet은 ELMo와 GPT의 AR(AuotRegressive) model과 BERT의 AE(Auto Encoding)model의 장점을 합쳐 놓은 것이다.
AR, AE
AE모델은 문장을 bidirectional하게 한꺼번에 받고 masked token을 복원하는 과정으로 학습이 진행된다.
하지만 masked token은 문장에서 독립적으로 존재하기 때문에 문장 내 의존관계(dependency)를 따질 수 없다.
반면 AR모델은 문장을 sequential하게 순차적으로 읽어 나간다.

하지만 AR의 경우 문장을 단방향으로만 보기 때문에 앞뒤 문맥을 파악하지 못한다는 단점이 있다. ELMo는 마지막 layer에서 forward LSTM과 backward LSTM의 결과값을 모두 사용하기는 하지만 각각 따로 학습하기 때문에 완전한 양방향 모델이라고 할 수는 없다.
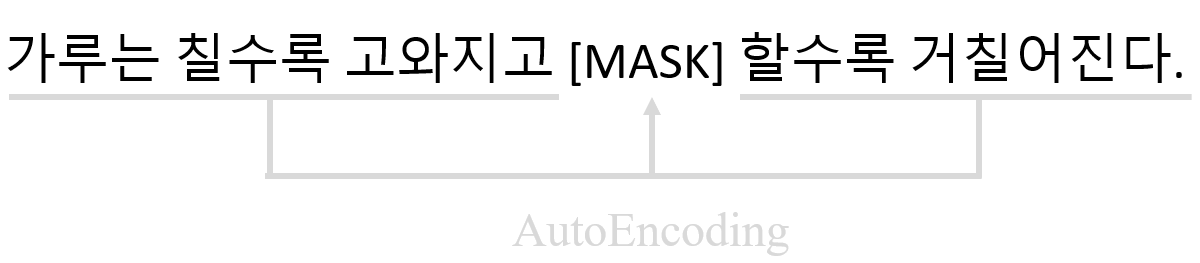
하지만 XLNet을 개발한 Yang et al.(2019)는 두 방식에 대한 문제점을 해결하기 위해 두 모델이 가지는 장점만 합쳐보았다. 이를 Permutation language model라고 부른다. 이 모델은 token을 랜덤으로 셔플한 후 셔플된 순서를 학습한다. 아래 예시처럼 ‘거칠어진다, 칠수록, 말은, 고와지고, 가루는’을 받아서 ‘할수록’을 예측하는 것이다.

이러한 방식으로 학습을 하면 token들을 순차적으로 학습하는 AR model과 학습 방향을 같지만 결과적으로 양방향으로 문맥을 파악할 수 있다.
5.1 Experiment 1, 2 result: agreement in clefts, agreement in indirect interrogatives
LSTM RNNs로 진행한 동일한 실험(cleft sentence, embedded question)을 XLNet으로 진행했을 때 아래와 같은 결과가 나왔다.
위 표를 보면 XLNet도 대부분 겹침이 많은 것을 볼 수 있다. BERT의 단점을 보완한 모델이라고는 하나, BERT보다도 성능이 좋지 않았다.
6. GPT-2
GPT-2는 Radford et al.(2019)논문에서 제안된 모델로, Transformer를 기반으로 하는 unsupervised model인 GPT의 후속 모델이다. 해당 모델은 다양한 task를 수행할 수 있도록 domain specific하지 않은 다양한 raw data를 학습한다. 본 논문에서는 GPT-2 medium model(3억 4천만개 parameter version)을 사용한다.
GPT-2에 대해 진행한 실험 1-4의 결과는 아래와 같다.
6.1 Experiment 1 result: agreement in clefts
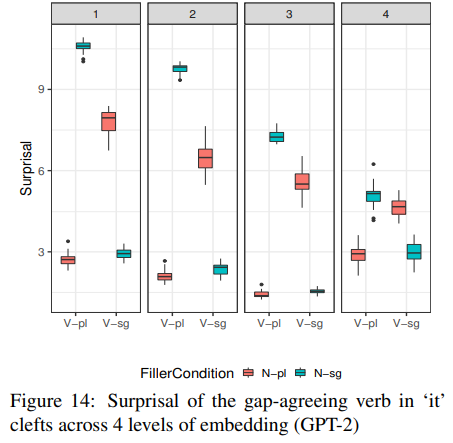
실험1의 결과, 모든 embedding level에서 정문(주어-동사 일치)의 surprisal이 유의미하게 나타났다. 그리고 위 표를 보면 embedding level이 깊어짐에 따라 각 condition간의 차이가 줄어드는 것을 확인할 수 있는데, 본 논문에서는 이러한 현상에 대해 embedding level이 깊어질수록 dependency가 줄어드는 결과라고 해석했다.
6.2 Experiment 2 result: agreement in indirect interrogatives
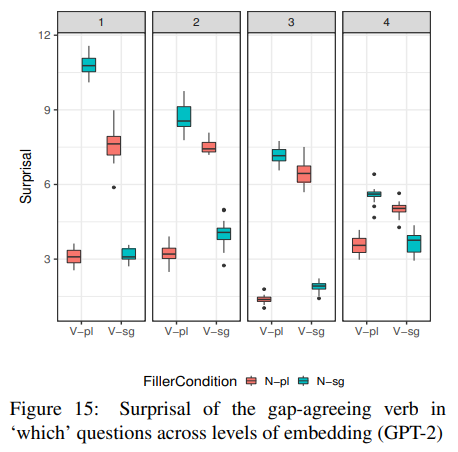
실험 2도 1과 같이 모든 embedding level에서 주어 동사 일치와 불일치 간의 surprisal이 뚜렷하게 구분된다. 잘 파악하고 있다.
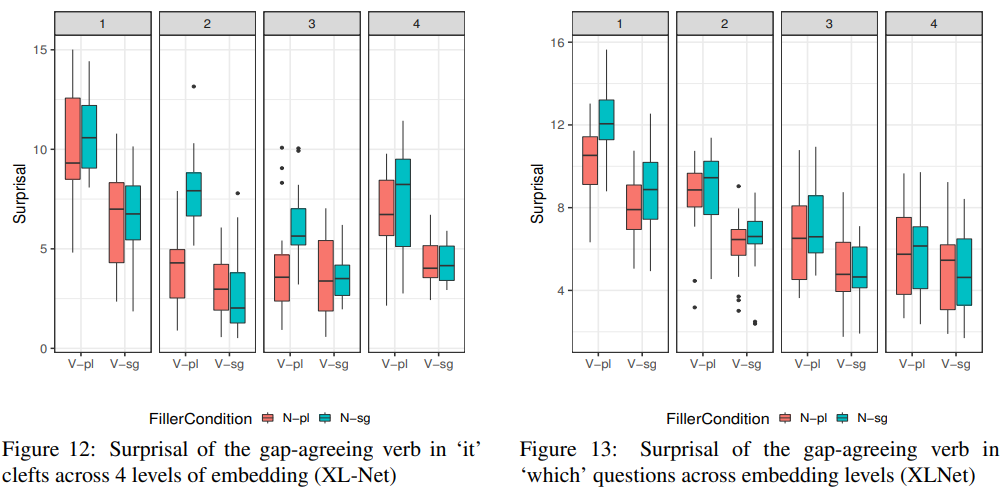
6.3 Experiment 3 result: Filler-gap surprisal in subject-inverted interrogatives
앞서 말했듯이 첫 번째와 네 번째 박스가 비문이고 두 번째와 세 번째가 정문이다. 비문에 해당하는 surprisal이 정문보다 높게 나와 모델이 학습을 잘 하는 것처럼 보이지만 본 논문에 따르면 wh-GAP과 nwh-nGAP이 둘 다 정문이기 때문에 surprisal이 비슷하게 나와야 하지만 wh-gap의 surprisal이 더 높게 나타나고 있다. 본 논문에서는 이와 같은 점이 조금 아쉽지만 전반적으로 주어-동사 도치 의문문의 dependency를 어느정도 잘 처리하고 있다고 볼 수 있다고 해석하였다.
!!!!!!!! wh-GAP과 nwh-nGAP의 surprisal이 비슷해야 한다고…? 글쎄… 이는 유표성과 관련된다. wh-GAP과 nwh-nGAP 중 nwh-nGAP이 더 unmarked form이다. 자연어에서는 wh-question보다 non wh-question이 더 많이 쓰이기 때문에 사용 빈도 측면에서도, syntactic complexity 측면에서도 nwh-nGAP의 surprisal이 낮은 것이 당연하다. 오히려 모델이 이를 잘 포착한 것으로 보인다. 별로 아쉬운 결과가 아니라고 생각한다.
6.4 Experiment 4 result: Filler-gap surprisal in uninverted indirect interrogatives
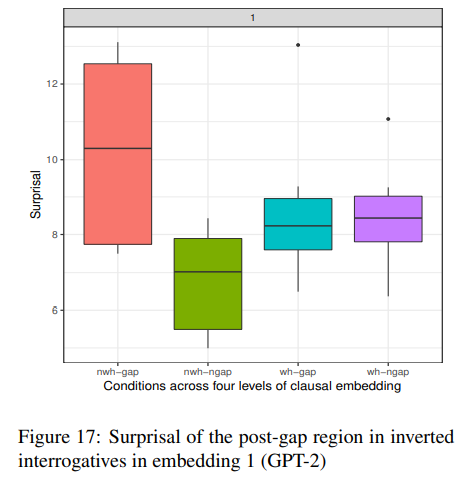
위 표에서 세 번째와 네 번째 박스, 즉 wh-GAP(정문)과 wh-nGAP(비문)의 surprisal차이가 거의 나타나지 않는다는 점은 아쉽지만 전반적으로 나쁘지 않은 결과를 보이고 있다.
!!!!!!!! 이 논문에서는 nwh-nGAP과 wh-GAP의 차이가 없다고 하는데 잘못된 설명 같다. Figure 17은 실험 4에 대한 그림인데 아래 설명은 inverted interrogative라고 되어있고 Figure 16에는 uninverted라고 되어 있다. 둘이 설명이 바뀐게 아닌가요…?
7. Discussion
실험 결과를 바탕으로 모델들의 성능은 XLNet, Transformer-XL < LSTM < GPT-2, BERT이다. GPT-2와 BERT가 다른 모델들보다 좋은 성과를 보이긴 했지만 주어진 dependency condition에 따라 성능이 크게 달라지는 양상을 보임으로써 많은 양의 데이터로 학습한 결과물이어도 아직은 불안정하다는 것을 확인할 수 있었다.
Reference
Da Costa.J et al.”Assessing the ability of Transformer-based Neural Models to represent structurally unbounded dependencies,”Association for Computational Linguistics.2020
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860.
https://mlexplained.com/2019/06/30/paper-dissected-xlnet-generalized-autoregressive-pretraining-for-language-understanding-explained/
https://openai.com/blog/language-unsupervised/
https://openai.com/blog/better-language-models/
https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances inneural information processing systems (pp. 5998-6008).
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog,1(8), 9.
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. URL https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf
Jozefowicz, R., Vinyals, O., Schuster, M., Shazeer, N., & Wu, Y. (2016). Exploring the limits of language modeling. arXiv preprintarXiv:1602.02410.
Maria M. Piñango, Emily Finn, Cheryl Lacadie, and R. Todd Constable (2016). The Localization of Long-Distance Dependency Components:Integrating the Focal-lesion and Neuroimaging Record. Front Psychol. 2016; 7: 143
- 1. Introduction
- 2. LSTM RNNs
- 3. Transformer-XL
- 3.1 Experiment 1, 2 result: agreement in clefts, agreement in indirect interrogatives
- 3.2 Experiment 3: Filler-gap surprisal in subject-inverted interrogatives
- 3.2.1 Experiment 3 result: Filler-gap surprisal in subject-inverted interrogatives
- 3.3 Experiment 4: Filler-gap surprisal in uninverted indirect interrogatives
- 3.3.1 Experiment 4 result: Filler-gap surprisal in uninverted indirect interrogatives
- 4. BERT
- 4.1 Experiment 1 result: agreement in clefts
- 4.2 Experiment 2 result: agreement in indirect interrogatives
- 4.3 Additional Experiment 1 result
- 4.4 Experiment 3, 4 result: Filler-gap surprisal in subject-inverted interrogatives, Filler-gap surprisal in uninverted indirect interrogatives
- 4.5 Additional Experiment 2 result
- 5. XLNet
- 6. GPT-2
- 7. Discussion
- Reference
1. Introduction
본 연구에서는 영어의 장거리 의존문장을 여러 학습 모델에서 어떻게 처리하는지에 대해 실험한다. 장거리 의존 구문이란 자연어가 가지고 있는 sequential 한 속성과 더불어 hierarchical한 속성을 가지고 있다는 대표적인 예시이다. 영어에서 나타나는 대표적인 장거리 의존 구문은 WH-question, Relative clause, Topicalization이다. 장거리 의존 구문에 대한 자세한 설명은 Long-Distance Dependency 여기에 있다.
장거리 의존 문장과 같이 복잡한 구조를 가진 문장을 잘 파악하지 못하면 아래와 같은 오류를 낼 수 있기 때문에 자연어처리 분야에서의 장거리 의존 구문 처리는 매우 중요하다.
It was the lawyer(s) who I think you said (GAP) was/were upset.
-> It was the lawyer who I think you said (GAP) was/*were upset.
-> It was the lawyer(s) who I think you said (GAP) *was/were upset.
따라서 본 연구에서는 딥러닝 모델들이 다양한 형태의 장거리 의존 구문을 잘 처리하는지 알아보고자 한다.
2. LSTM RNNs
여기에서 사용되는 모델은 Gulordava model과 Google model이다. Gulordava model은 English Wikipedia corpus 9000만 token으로 학습되었고 650 unit hidden layer 두 개를 가진다. Google model은 10억개의 Word Benchmark(Chelba et al., 2013)로 학습되었고 8196 unit을 가진 두 개의 hidden layer로 이루어져 있다. 그리고 character level CNN의 output을 LSTM의 input으로 사용한다. 이 두 모델은 아래와 같은 두 가지 조건 하에 사용된다. 기본적인 실험 방식은 Wilcox et al.(2019b)를 기반으로 한다.
2.1 Experiment 1: agreement in clefts
첫 번째 조건은 cleft sentence(분열문)이다. 분열문은 한 문장이 두 부분으로 구성되어 있는 문장으로, it-that 강조구문을 생각하면 쉽다.
위 예문 a는 wh-관계절로 이루어진 문장으로, it was the lawyer부분과 삽입절 I think로 나뉠 수 있다. 위 예문 a, b, c, d는 순서대로 삽입절의 개수가 점점 추가되는 것을 확인할 수 있다. 이에 따라 내포 수준(LEVEL)도 증가하는 것도 볼 수 있다.
본 실험에서는 2x2x4 factorial design(삽입절을 통해 강조되는 the lawyer(s)는 단수일 경우와 복수일 경우가 존재하며 이에 따라 동사의 경우도 2가지(단수/복수), 위 예문처럼 삽입절이 추가되는 4가지 문장)을 이용한 20 cleft item을 만들어 총 320문장을 가지고 실험을 진행한다.
2.2 Experiment 2: agreement in indirect interrogatives
두 번째 조건은 indirect interrogative(간접의문문)이다. 이는 embedded question이라고도 하는데, 종속절로 기능하는 의문문이다.
여기에서도 마찬가지로 2x2x4 factorial design, 20 cleft items, 320 sentences로 실험이 진행된다.
2.3 Result
두 조건에 대한 결과는 Surprisal로 제시된다. 본 실험에서는 수일치를 확인하고자 하기 때문에 RNN이 수일치에 성공했다면 Surprisal 수치가 낮을 것이고 틀렸다면 높을 것이다.
Surprisal(의외성/놀람)
Wilcox et al. (2018)에서는 log inverse probability라고 하며 아래와 같은 공식을 제시하였다. 위 수식에서 x_i는 예측하고자 하는 단어이고 h_{i-1}은 x_i 이전의 hidden state 값이다. 따라서 맢선 맥락을 바탕으로 해당 단어에 대해 기대하는 정도를 surprisal로 나타낸다. 값이 낮을수록 의외가 아닌 것이고 높을수록 의외인 것이다. (공식)
CoNLL에서 주로 사용되는 개념으로, Surprisal(의외성)은 사건이 일어나지 말아야하는 환경에서 나타날 경우에 나타나는 놀라움의 정도를 나타낸다. 예를 들어 초등학교 동창을 같은 동네에서 마주친 것보다 휴가지로 떠난 하와이에서 마주친 경우가 의외성의 수준이 더 높은 것이다.
2.3.1 Experiment 1 result: agreement in clefts
위 표에서 npl(빨간 박스)은 복수명사, nsg(초록 박스)는 단수명사를 나타낸다. 그리고 표의 x축에는 vpl(복수 동사)와 vsg(단수동사)가 나와있고 위에 제시된 숫자는 삽입절 내포 수준을 나타낸다. RNN이 제대로 학습했다면 명사가 복수일 때 동사가 복수여야 하기 때문에 초록색 박스보다 빨간색 박스의 수치가 낮게 나타나야 한다. 하지만 표를 보면 두 박스가 나타내는 수치의 차이가 거의 없다. google model에서는 삽입절이 많을수록 surprisal값이 높아지는 것을 볼 수 있다(예측을 잘 하지 못한다).
2.3.2 Experiment 2 result: agreement in indirect interrogatives
두 번째 실험의 결과도 첫 번째 실험처럼 전반적으로 겹침이 많은 것을 볼 수 있다. 따라서 Gulordava와 Google model은 장거리 의존 구문의 형태 통사적인 특징을 잘 학습하지 못한다는 것을 알 수 있다.
3. Transformer-XL
Transformer-XL은 기존 Transformer의 self-attention network에 ‘recurrence’개념을 도입한 모델이다. 기존 Transformer는 현재의 정보를 처리할 때 이전 정보가 단절되는데 Transformer-XL은 recurrence를 도입하여 이전 정보가 현재 정보에도 전파되도록 한다. Dai et al.(2019)에 따르면 RNN보다 80%더 긴 dependency를 학습할 수 있다고 한다. 이를 증명하기 위해 본 논문에서는 RNN으로 진행한 실험을 동일하게 진행하였다.
3.1 Experiment 1, 2 result: agreement in clefts, agreement in indirect interrogatives
위 그래프는 실험 1의 결과를 시각화한 것이다. 내포수준 1과 3에서만 주-동 수 일치 surprisal이 불일치 surprisal보다 낮게 나왔다. 즉 내포수준 1과 3에서만 제대로 구분을 하고 나머지는 못하는 것이다. 따라서 Transformer-XL의 성능이 RNN보다 아주 조금 더 좋다는 것을 알 수 있다.
실험 2에서도 결과가 좋지 않았다.
3.2 Experiment 3: Filler-gap surprisal in subject-inverted interrogatives
실험3은 주어가 도치된 의문문의 dependency에 대한 실험이다. 아래 예시 문장의 경우, talk about의 목적어가 what으로 대체되고 what이 절의 맨앞으로 이동한 것이다. 이때 what이 원래 있던 자리에 GAP이 생기는데 이 GAP과 what 사이에 dependency가 발생한다. GAP자리에 목적어 it을 삽입하면 talk about의 목적어가 두개(what과 it)가 되어버리기 때문에 비문이 된다. 따라서 실험3은 what과 GAP사이의 dependency를 모델이 잘 처리할 수 있는지 알아보는 것이다.
20개의 item 대해 WH-question이 있는 문장과 없는 문장 그리고 GAP이 있는 것과 없는 것 그리고 내포수준 1-4까지 해서 20x2x2x4, 총 320문장으로 실험을 진행한다.
그리고 GAP뒤에 나오는 item, 위 예시에서는 at뒤에 나오는 item의 softmax값(확률값)을 추출한다.
본 논문의 저자인 Rui P. Chaves는 island effect를 전공한 사람이다. 그래서 experiment syntax 연구 모델을 활용하여 본 실험을 설계한 것이다. a, b, c, d에서 b와 c는 정문이고 a와 d는 비문이다. 이와 같은 2x2 design은 a-b, a-c, c-d 각각이 syntactic constraint를 기준으로 하나의 minimal pair가 된다. 이런 식으로 2x2 conditional design으로 정석적인 experiment syntactic method를 사용하였다. 20개의 item은 각 항목마다 lexicalization을 해서 20개씩 분포했다는 말이다. 이러한 metric은 human evaluation에서도 매우 좋은 설계이다.
3.2.1 Experiment 3 result: Filler-gap surprisal in subject-inverted interrogatives
위 boxplot은 내포수준 1에 대한 결과를 시각화 한 것이다. 그래프 상에서 두 번째와 세 번째 박스가 정문이고 첫 번째와 네 번째 박스가 비문에 해당한다(wh가 없을 때는 gap도 없어야 정문이고 wh가 있을 때는 gap도 있어야 정문이 된다.) 따라서 모델이 예측을 잘 했다면 두 번째와 세 번째 surprisal이 첫 번째와 네 번째보다 낮아야 한다. 하지만 실험 결과, 정문에 해당하는 surprisal이 비문에 해당하는 surprisal보다 높게 나타났다. 나머지 내포수준에서도 전반적으로 결과가 좋지 않아 Transformer-XL이 주어 도치 의문문 처리 성능이 좋지 않음이 확인되었다.
최근 정략적 기반의 empirical linguistic study에서 boxplot을 이용한 시각화가 많이 보이고 있다.
3.3 Experiment 4: Filler-gap surprisal in uninverted indirect interrogatives
실험 4에서는 모델이 도치가 안 된 간접 의문문에서의 dependency를 파악할 수 있는지를 확인한다. 일반적으로 의문문은 주어와 동사가 도치되지만 의문문이 모절 안에 내포될 경우에는 도치 없이 실현된다. What과 GAP사이에 dependency가 발생한다는 점은 실험 3과 동일하지만 We talked about과 같이 주어와 동사가 도치되지 않는 점이 차이이다.
3.3.1 Experiment 4 result: Filler-gap surprisal in uninverted indirect interrogatives
실험 4의 결과는 그냥 처참하다. 모든 embedding level에서 올바른 surprisal pattern이 관찰되지 않았다. Transformer-XL은 RNN보다 dependency처리 능력이 나쁘다고 볼 수 있다.
4. BERT
BERT에 대한 자세한 설명은 BERT여기에 있다.
4.1 Experiment 1 result: agreement in clefts
BERT에는 masked token이 사용되는데 본 실험에서는 be동사에 masking을 했다.
위 예문처럼 was나 were부분을 가려놓고 그 곳의 surprisal값을 구하는 방식으로 실험을 진행하였다. 정문이 비문보다 surprisal이 낮아야 한다. 위 boxplot을 보면 한 박스 내에서 1번과 4번이 낮고 2번과 3번이 높게 나타나 BERT 실험 결과가 통계적으로 유효한 차이를 보이고 있음을 알 수 있다.
4.2 Experiment 2 result: agreement in indirect interrogatives
실험 2는 간접 의문문과 관련된 실험이다.
여기에서도 실험 1과 마찬가지로 한 박스 내에서 1번과 4번이 나머지보다 surprisal이 낮아야 한다. 내포수준 1, 2, 3에서는 잘 처리가 되고 있고 level4에서는 조금 결과가 안 좋다. 조금 아쉬운 결과지만 다른 모델들보다 BERT의 결과가 가장 잘 나왔다.
4.3 Additional Experiment 1 result
위 실험 결과와 같이 BERT가 언어를 잘 처리한다는 결과가 나왔는데 정말로 잘 처리하는 것인가를 알아보기 위해 추가적인 실험을 진행하였다. long-distance dependency처럼 생겼지만 long-distance dependency를 처리하는 것처럼 처리하면 안 되는 경우에 BERT가 어떤 반응을 보이는지 살펴보았다. 예를 들어 앞에 나온 NP와 뒤에 나오는 동사의 수가 다른 조건을 주어 헷갈리게 하는 것이다.
위 예문을 보면 동사는 the boy/the boys가 아닌 she/he와 we/they에 걸려야 정문이 되는 문장인데 동사가 the boy/the boys에 걸려서 비문이 되었다.
위 그래프는 이 실험에 대한 결과이다. 본 실험은 앞에 있는 NP와 동사의 단복수가 다른 조건에서 surprisal이 낮아야 하는 상황이기 때문에 다른 실험들의 결과와는 반대로 나타나야 한다. 위 그래프를 보면 BERT가 문장을 잘 파악해서 주-동 수일치를 잘 식별한 것을 알 수 있다.
4.4 Experiment 3, 4 result: Filler-gap surprisal in subject-inverted interrogatives, Filler-gap surprisal in uninverted indirect interrogatives
이 실험은 앞선 실험과는 달리 long distance dependency를 도치와 비도치 의문문 조건에서 살펴본다.
10번과 11번 예문을 보면 뒤에 있는 at the party에서 at을 masking 해놓고 이것의 softmax값을 도출하면서 surprisal값을 낸다. 정문인 경우 at이 있어야 하기 때문에 surprisal이 낮게 나타날 것이고 비문의 경우에는 at이 있으면 이상하니까 surprisal이 높을 것이다. 정문인 b와 c는 boxplot에서 2번과 3번에 대응되기 때문에 2번과 3번은 낮아야 하고 1번과 4번이 높게 나와야 하는데 잘 처리되고 있음을 볼 수 있다.
4.5 Additional Experiment 2 result
BERT가 우수한 성과를 내는 이유 중 하나는 양방향 학습이라고 볼 수 있다. 양방향으로 학습하며 후행 성분을 고려하는 특성으로, 앞선 다른 모델들에 대한 실험과 골자는 동일하지만 critical item에 yesterday repeatedly, again, then과 같은 부사를 넣어 실험을 진행한다.
(12)b,c는 정문이고 a, d는 비문이다.
위 boxplot에서 두 번째와 세 번째가 b와 c에 대응하고 첫 번째와 네 번째는 a와 d에 대응한다. 위 표를 보면 정문이 비문보다 낮게 나타나야 하는데 지금까지 진행한 BERT실험들과는 좋지 않은 결과가 나왔다. 이는 BERT의 처리 능력에도 한계가 있다는 것을 시사한다.
5. XLNet
XLNet은 ELMo와 GPT의 AR(AuotRegressive) model과 BERT의 AE(Auto Encoding)model의 장점을 합쳐 놓은 것이다.
AR, AE
AE모델은 문장을 bidirectional하게 한꺼번에 받고 masked token을 복원하는 과정으로 학습이 진행된다.
하지만 masked token은 문장에서 독립적으로 존재하기 때문에 문장 내 의존관계(dependency)를 따질 수 없다.
반면 AR모델은 문장을 sequential하게 순차적으로 읽어 나간다.
하지만 AR의 경우 문장을 단방향으로만 보기 때문에 앞뒤 문맥을 파악하지 못한다는 단점이 있다. ELMo는 마지막 layer에서 forward LSTM과 backward LSTM의 결과값을 모두 사용하기는 하지만 각각 따로 학습하기 때문에 완전한 양방향 모델이라고 할 수는 없다.
하지만 XLNet을 개발한 Yang et al.(2019)는 두 방식에 대한 문제점을 해결하기 위해 두 모델이 가지는 장점만 합쳐보았다. 이를 Permutation language model라고 부른다. 이 모델은 token을 랜덤으로 셔플한 후 셔플된 순서를 학습한다. 아래 예시처럼 ‘거칠어진다, 칠수록, 말은, 고와지고, 가루는’을 받아서 ‘할수록’을 예측하는 것이다.
이러한 방식으로 학습을 하면 token들을 순차적으로 학습하는 AR model과 학습 방향을 같지만 결과적으로 양방향으로 문맥을 파악할 수 있다.
5.1 Experiment 1, 2 result: agreement in clefts, agreement in indirect interrogatives
LSTM RNNs로 진행한 동일한 실험(cleft sentence, embedded question)을 XLNet으로 진행했을 때 아래와 같은 결과가 나왔다.
위 표를 보면 XLNet도 대부분 겹침이 많은 것을 볼 수 있다. BERT의 단점을 보완한 모델이라고는 하나, BERT보다도 성능이 좋지 않았다.
6. GPT-2
GPT-2는 Radford et al.(2019)논문에서 제안된 모델로, Transformer를 기반으로 하는 unsupervised model인 GPT의 후속 모델이다. 해당 모델은 다양한 task를 수행할 수 있도록 domain specific하지 않은 다양한 raw data를 학습한다. 본 논문에서는 GPT-2 medium model(3억 4천만개 parameter version)을 사용한다.
GPT-2에 대해 진행한 실험 1-4의 결과는 아래와 같다.
6.1 Experiment 1 result: agreement in clefts
실험1의 결과, 모든 embedding level에서 정문(주어-동사 일치)의 surprisal이 유의미하게 나타났다. 그리고 위 표를 보면 embedding level이 깊어짐에 따라 각 condition간의 차이가 줄어드는 것을 확인할 수 있는데, 본 논문에서는 이러한 현상에 대해 embedding level이 깊어질수록 dependency가 줄어드는 결과라고 해석했다.
6.2 Experiment 2 result: agreement in indirect interrogatives
실험 2도 1과 같이 모든 embedding level에서 주어 동사 일치와 불일치 간의 surprisal이 뚜렷하게 구분된다. 잘 파악하고 있다.
6.3 Experiment 3 result: Filler-gap surprisal in subject-inverted interrogatives
앞서 말했듯이 첫 번째와 네 번째 박스가 비문이고 두 번째와 세 번째가 정문이다. 비문에 해당하는 surprisal이 정문보다 높게 나와 모델이 학습을 잘 하는 것처럼 보이지만 본 논문에 따르면 wh-GAP과 nwh-nGAP이 둘 다 정문이기 때문에 surprisal이 비슷하게 나와야 하지만 wh-gap의 surprisal이 더 높게 나타나고 있다. 본 논문에서는 이와 같은 점이 조금 아쉽지만 전반적으로 주어-동사 도치 의문문의 dependency를 어느정도 잘 처리하고 있다고 볼 수 있다고 해석하였다.
!!!!!!!! wh-GAP과 nwh-nGAP의 surprisal이 비슷해야 한다고…? 글쎄… 이는 유표성과 관련된다. wh-GAP과 nwh-nGAP 중 nwh-nGAP이 더 unmarked form이다. 자연어에서는 wh-question보다 non wh-question이 더 많이 쓰이기 때문에 사용 빈도 측면에서도, syntactic complexity 측면에서도 nwh-nGAP의 surprisal이 낮은 것이 당연하다. 오히려 모델이 이를 잘 포착한 것으로 보인다. 별로 아쉬운 결과가 아니라고 생각한다.
6.4 Experiment 4 result: Filler-gap surprisal in uninverted indirect interrogatives
위 표에서 세 번째와 네 번째 박스, 즉 wh-GAP(정문)과 wh-nGAP(비문)의 surprisal차이가 거의 나타나지 않는다는 점은 아쉽지만 전반적으로 나쁘지 않은 결과를 보이고 있다.
!!!!!!!! 이 논문에서는 nwh-nGAP과 wh-GAP의 차이가 없다고 하는데 잘못된 설명 같다. Figure 17은 실험 4에 대한 그림인데 아래 설명은 inverted interrogative라고 되어있고 Figure 16에는 uninverted라고 되어 있다. 둘이 설명이 바뀐게 아닌가요…?
7. Discussion
실험 결과를 바탕으로 모델들의 성능은 XLNet, Transformer-XL < LSTM < GPT-2, BERT이다. GPT-2와 BERT가 다른 모델들보다 좋은 성과를 보이긴 했지만 주어진 dependency condition에 따라 성능이 크게 달라지는 양상을 보임으로써 많은 양의 데이터로 학습한 결과물이어도 아직은 불안정하다는 것을 확인할 수 있었다.
Reference
Da Costa.J et al.”Assessing the ability of Transformer-based Neural Models to represent structurally unbounded dependencies,”Association for Computational Linguistics.2020
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860.
https://mlexplained.com/2019/06/30/paper-dissected-xlnet-generalized-autoregressive-pretraining-for-language-understanding-explained/
https://openai.com/blog/language-unsupervised/
https://openai.com/blog/better-language-models/
https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances inneural information processing systems (pp. 5998-6008).
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog,1(8), 9.
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. URL https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf
Jozefowicz, R., Vinyals, O., Schuster, M., Shazeer, N., & Wu, Y. (2016). Exploring the limits of language modeling. arXiv preprintarXiv:1602.02410.
Maria M. Piñango, Emily Finn, Cheryl Lacadie, and R. Todd Constable (2016). The Localization of Long-Distance Dependency Components:Integrating the Focal-lesion and Neuroimaging Record. Front Psychol. 2016; 7: 143