



Sequence to Sequence(Seq2Seq)
11 Nov 2019 | NLP
Seq2Seq 실습 코드: https://finddme.github.io/natural%20language%20processing/2019/11/11/Seq2SeqCode/
- 1.Machine Translation
- 1.1 Why is it so hard?
- 1.2 History
- 2. Sequence to Sequence Model
- 2.1 Architecture of seq2seq model
- 2.2 Experiment
- 2.3 Model Analysis
- 2.4 Teacher Forcing
- 2.5 Applications of seq2seq
- 2.6 Limitation
- Reference
해당 게시물에서 소개할 Seq2Seq모델은 기계번역에 사용되는 것으로 잘 알려져 있다. 따라서 모델 설명 이전에 가볍게 번역 과제에 대해 언급하도록 하겠다.
1.Machine Translation
1.1 Why is it so hard?
번역 과제는 source language의 의미를 target language로 옮겨 다른 두 언어가 같은 의미를 지니게하도록 하는 작업이다. 해당 작업은 여러 자연어처리 과제 중 어려운 과제에 속한다. 아래는 번역 과제가 어려운 이유이다:
1) 인간의 언어는 단순히 합성성의 원리로만 이해될 수 없다. 즉 의미를 지닌 단어들을 쭉 나열한다고 해서 나열된 단어들의 전체 의미가 각 단어들의 의미의 합과 같지 않다는 것이다. 대표적으로 관용구를 예로 들 수 있다.
2) 함축을 활용하여 다양한 정보를 전달한다.
-
인간은 말해진 것 이상의 의미(대화에서 내포하고있는 의미)를 주고 받는다. 이를 해석하기 위해서는 협력원리가 작용한다. 협력의 원리에는 양, 질, 관계, 태도 이렇게 네 가지의 대화의 격률이 존재하는데 대화과정에서 대화격률이 의도적으로 위반되는 경우에도 협력원리가 유지된다는 가정하에 화자는 특정한 의미를 함축하게 된다. 또한 청자도 화자의 발화로부터 전달되는 문자적 의미와 배경지식 등을 고려하여 화자의 함축된 의미를 추론함으로써 의사소통을 한다.
-
자연어의 표현은 의미가 고정되지 않고 대화 문맥에 따라 의미가 달라진다.
-
항진명제와 은유가 빈번히 사용된다.
3) 특히 한국어 같은 경우 생략 현상과 강세 변화에 따른 의미 변화가 다른 언어에 비해 더 많이 나타난다.
1.2 History
이어서 기계번역의 역사에 대해서도 짚어보고 가겠다.
1) RBMT(Rule-Based Machine Translation)
: 전통적인 번역 방식인 규칙 기반 기계번역이다. 말 그대로 형태, 통사, 의미 정보가 포함된 광범위한 어휘소와 대규모 규칙을 필요로 하는 번역 방식이다. 해당 규칙은 사람이 만들어야 하기 때문에 많은 자원과 시간이 소모된다. 또한 언어는 매일매일 지속적으로 변화한하기에 번역 언어쌍 확장은 필수적으로 이루어져야 하는데 이때 번역 품질 향상을 위해 전문가가 매번 새로운 규칙을 찾아내 적용해야한다. 따라서 지속적이 투자가 필요하기 때문에 실제 산업에서는 사용률이 저조했다.
2) SMT(Statistical Machine Translation)
: 통계 기반 기계번역으로 대량의 양방향 코퍼스에서 통계를 얻어내 번역 시스템을 구성한다. 언어쌍 업로드가 RBMT에 비해 비교적 빠르고 간단하다.
3) NMT(Neural Machine Translation) :
딥러닝 기반의 기계번역. 해당 방식의 도입으로 인해 기계번역 발전에 박차를 가할 수 있었다. 이전까지 연구된 기계번역 방식보다 NMT가 잘 작동하는 이유는 다음과 같다:
-
End-to-end Model $\rightarrow$ SMT의 경우 여러가지 모듈로 구성되어 시스템이 복잡해 훈련에 어려움이 있었던 반면, NMT는 단 하나의 모델을 사용함으로써(전체를 하나의 모델로 한번에 학습함으로써) 시스템을 단순화 하여 성능을 높였다.
-
Better language model $\rightarrow$ 신경망 언어모델(Neural Network Language Model)을 기반으로 하는 구조이기에 기존의 SMT에서 사용하던 n-gram 방식의 언어 모델보다 강력하다. 희소성(sparseness)문제가 해결 되었으며, 자연스러운 번역을 가능하게 한다. (간단히 말하자면 모델 자체가 더 나아졌다는 것이다.)
-
Great context embedding $\rightarrow$ Neural Network모델은 데이터를 압축시키는 것에 있어 좋은 성능을 자랑한다. 따라서 문장의 의미를 벡터화(vectorize)하는 능력이 뛰어납니다. 따라서, 노이즈나 희소성(sparseness)문제를 이전보다 잘 해결할 수 있다.(간단히 말하자면 임베딩 기능이 향상되었다는 것이다.)
2. Sequence to Sequence Model
이제 본격적으로 Seq2Seq이라는 모델에 대해 소개하도록 하겠다. 일반적인 Deep Neural Network같은 경우 다양한 분야에서 좋은 성과를 보였으나 sequence data처리에는 큰 성과를 보이지 못 했다. 이는 input dimension과 output dimension이 고정되어 있기 때문이다. 물론 convolution연산의 경우 input의 크기가 정해져 있지 않지만 Multi-Layer-Perceptron의 경우에는 입력의 차원과 출력의 차원을 정한 후에 학습을 시작한다. 이러한 방식은 이미지 데이터와 같이 크기가 고정된 데이터를 처리할 경우에 유용하게 사용될 수 있다. 하지만 인간이 주고받는 언어의 입력과 출력 크기는 상황에 따라, 사람에 따라 매우 상이하다. 따라서 위에서 언급된 모델들로는 인간의 언어를 학습시키는 것에 어려움이 있다. 이러한 문제점을 해결하기 위해 고안된 모델이 오늘 설명할 seq2seq모델이다.
위에서 언급한 바와 같이 seq2seq은 입, 출력의 크기가 정해지지 않아도 학습이 가능한 모델이다. 이는 모델의 구조를 살펴보면 그것이 가능한 이유를 알 수 있다. seq2seq 구조는 크게 Encoder와 Decoder로 나뉜다. Encoder는 입력문장을 받아 그것을 벡터로 변환하는 역할을 하고, Decoder의 경우에는 Encoder를 통해 만들어진 벡터를 사용하여 다시 또 다른 문장을 만들어 내는 것이다. Decoder 부분에서 Generator라는 모듈을 따로 떨어트려 살펴보면 이는 Decoder의 출력 벡터들을 Softmax를 통과시켜 가장 높은 확률을 가진 단어 하나를 추출해 내는 작업이 이루어지는 곳이다. Seq2seq모델을 수식화 하면 다음과 같이 표현할 수 있다:
\begin{matrix}
{\theta}^{ * } \approx argmax \ P(Y|X ;\theta) \ where\ X=\ { x_1, x_2, x_3, …, x_n\ } , Y=\ { y_1, y_2, y_3, …, y_m\ }
\end{matrix}
위 수식을 통해 Seq2seq은 모델의 파라미터($\theta$)가 주어졌을 때 source data($X$)를 받아서 target data($Y$)를 가장 높은 확률의 값으로 반환할 때 해당 확률을 최대로 올리는, 즉 $P(Y|X ;\theta)$ 를 최대로 하는 모델 파라미터를 학습하는 모델이라는 것을 나타낸다.
Seq2seq모델은 말 그대로 sequence data가 들어가서 sequence data가 나오는 모델로, 간단히 말하자면 many-to-many방식의 RNN인데 encoder, decoder, generator를 통해 높은 확률의 결과 값을 도출하도록 학습하는 모델이다.
2.1 Architecture of seq2seq model
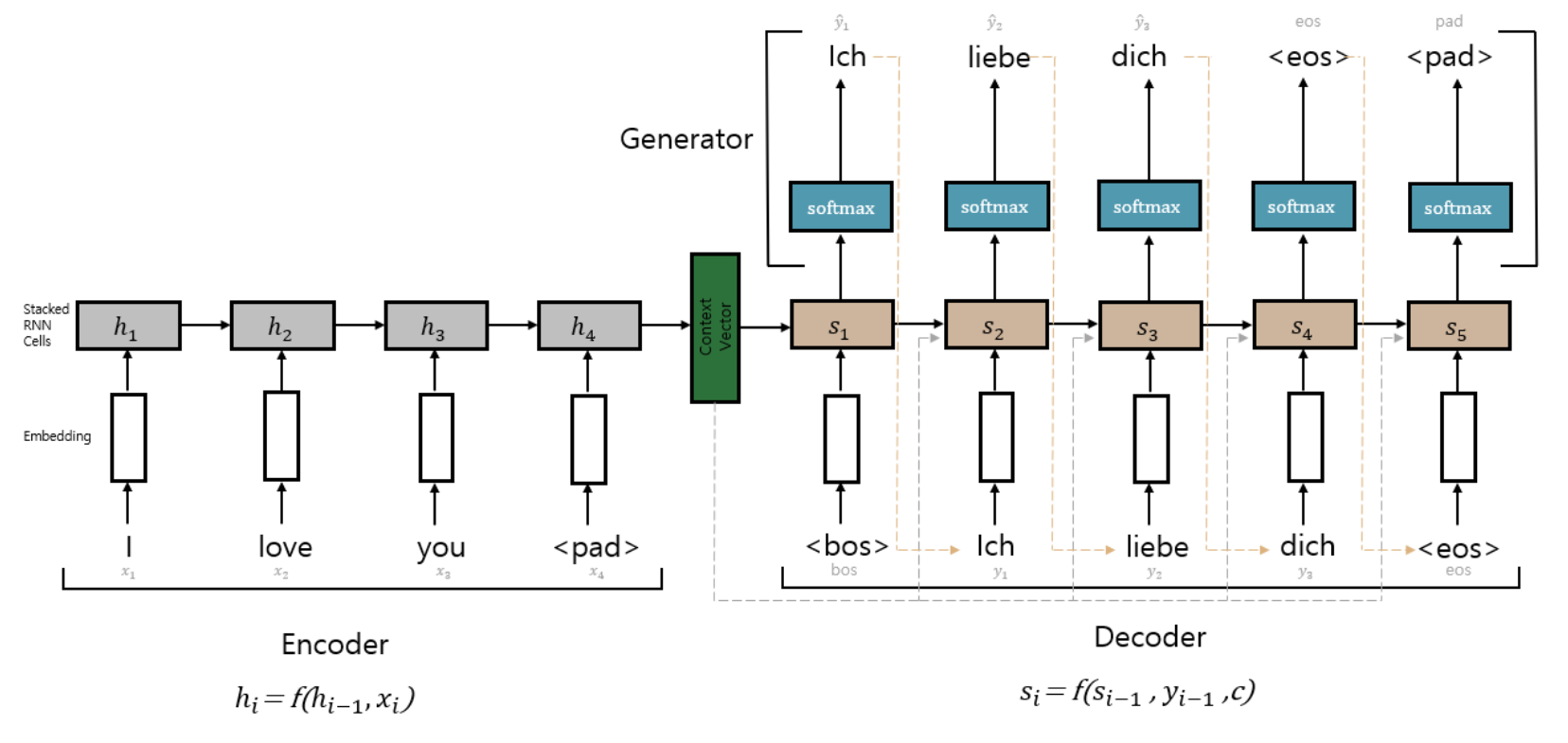
Illustrated by the author
위 그림을 보며 지금까지 개괄적으로 언급한 내용에 대해 조금 더 자세히 살펴보도록 하겠다.
$\circ$ Encoder
이곳에서는 $P(X)$를 모델링한다. 위 그림을 보면 $x_1$ (I), $x_2$ (love), $x_3$ (you)라는 입력이 순차적으로 입력되며 각각 embedding layer를 거치며 벡터화(vectorize) 되어 Stacked RNN Cell에 들어가는 것을 확인할 수 있다. 여기에서 Stacked RNN Cell은 Multi layer RNN이라고 생각하면 된다. 이곳에는 Vanilla RNN, LSTM, GRU, Bidirectional-RNN과 같은 RNN계열의 모델들이 사용될 수 있다(논문 Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation에서는 GRU를, Sequence to Sequence Learning with Neural Networks에서는 LSTM을 활용하였다). 각 입력에 대한 hidden state값들은 일반적인 RNN계열 모델들과 같이 다음 state로 넘어가서 해당 state의 input 값과 함께 입력된다. 그렇게 Encoder의 마지막 입력 값이 들어오면 padding 작업 후 Encoder부분의 마지막 hidden state값을 context vector(fixed-length vector)로 활용하여 Decoder로 넘긴다. 따라서 context vector는 Encoder정보를 함축하여 담고 있는 vector이다. Encoder를 수식으로 표현하면 다음과 같다.
\begin{matrix}
{ h }_ { t }^{ src }={ RNN }_ { enc }({ emb }_ { src } (x_t), { h }_ { t-1 }^{ src })
\end{matrix}
\begin{matrix}
{H}^{ src }= [h_1^{src}; {h}_ {2}^{ src }; \dots ; {h}_ {n}^{ src }]
\end{matrix}
위 수식은 time-step별로 RNNcell을 통과시킨 것을 나타낸다. ${ h }_{ t }^{ src }$는 $t$번째 source state의 hidden vector값을 뜻한다. 이는 Encoder부분의 RNN cell을 지나는데 해당 RNN cell에는 source data인 $x_t$의 embedding 값과 이전 hidden vector가 들어간다. 이렇게 나온 각 state의 hidden vector값은 모두 concatenate되어 ${ H }^{ src }$가 도출된다. 이는 사실상 코딩을 할 경우 아래와 같은 수식이 된다.
\begin{matrix}
{H}^{src}= {RNN}_ {enc}({emb}_ {src}(X),{ h }_ { 0 }^{src})
\end{matrix}
$\circ$ Decoder
Decoder부분의 경우 문장의 시작을 알리는 $BOS$(begin-of-sentence)token과 끝을 알리는 $EOS$(end-of-sentence)token이 존재한다. Decoder의 시작부분 같은 경우에는 context vector와 임의의 초기값으로 설정한 $y$(이전 state의 출력 값)와 $s$(이전 state의 hidden vector값)가 입력되어 첫 출력 값을 도출한다. 이후에는 context vector와 이전 state의 출력 값으로 나온 $y$ 즉, ${y}_{i-1}$와 이전 state의 hidden vector인 $s$ 즉, ${s}_{i-1}$이 Encoder에서와 같이 RNN계열의 모델에 입력된다. 여기에서 context vector는 항상 같은 값이 사용된다.
seq2seq모델의 진행 방식을 time-step에 대해 수식화 하자면 다음과 같다.
\begin{matrix}
{P}_ { \theta }(Y│X)=\prod_{t=1}^{m} {P}_ { \theta }(y_t |X, y_{<t})
\end{matrix}
\begin{matrix}
\log P_{ \theta }(Y|X)=\sum_{t=1}^{m} \log P_{ \theta }(y_t|X, y_{<t})
\end{matrix}
위 수식은 이전 time-step의 결과와 encoder로부터 도출된 결과($X$)를 기반으로 하여 target값($Y$)을 유추해내는 작업을 표현하고 있다.
아래 수식은 Decoder부분을 수식으로 표현한 것이다.
\begin{matrix}
{ h }_ { t }^{ tgt }={ RNN }_ { dec } ({ emb }_ { tgt }({ y }_ { t-1 }), { h }_ { t-1 }^{ tgt }) \ where \ { h }_ { 0 }^{ tgt } = { h }_ { n }^{ src } \ and \ y_0=BOS
\end{matrix}
위 수식을 살펴보면 ${ h }_{ t }^{ tgt }$ 는 $t$번째 target state의 hidden vector인데 이는 Decoder부분의 RNN cell에 이전 state의 결과 값($y_{t-1}$)을 embedding한 값과 이전 state에서 나온 hidden vector값이 입력되어 도출된다. 여기에서 주의 깊게 살펴볼 점은 decoder부분의 첫 시작에서는 $y$의 초기 값으로써 $BOS$를 입력한다는 것이다.
$\circ$ Generator
Generator부분에서는 Decoder부분의 RNN Cell을 거쳐 나온 값들이 softmax를 거쳐 0부터 1사이의 확률 값으로 변환되어 가장 높은 확률 값이 해당 state의 출력 값으로 도출된다. 아래는 Generator 부분을 수식화 한 것이다.
\begin{matrix}
\hat{ y }_ { t }=softmax({ linear }_ { hs\rightarrow \left\vert { V }_ { tgt } \right\vert }({ h }_ { t }^{ tgt })) \ and \ \hat{ y }_ { m }=EOS
\end{matrix}
Where $hs$ is hidden size of RNN, and $\left\vert { V }_{ tgt } \right\vert$ is size of output vocabulary.
위 수식에서 softmax는 비선형 함수임에도 그 속에 선형 함수가 들어있는 것을 볼 수 있다. 이는 decoder에서 도출된 각 state의 hidden vector값들을 0-1사이의 확률 값으로 변환하기 위해 차원을 늘려주는 작업이다. 그리고 여기에서 특기할 점은 decoder부분의 첫 입력 값으로 계산의 시작을 나타내는 초기값 $BOS$가 있듯이 decoder 계산의 종료를 알리는 $EOS$ token이 존재한다는 것이다.
2.2 Experiment
지금까지 seq2seq모델의 구조를 하나하나 뜯어 살펴보았는데 위와 같은 방식은 특히 긴 문장을 처리할 때 일반적인 RNN계열의 모델만 단순히 사용했을 보다 더 좋은 성능을 보이게 된다. 왜냐하면 RNN은 일반적인 feedforward neural network인데 즉, input($x_1$, $x_2$, $x_3$ $\dots$ $x_n$)에 대해 아래 수식을 반복하며 output($y_1$, $y_2$, $y_3$ $\dots$ $y_T$)을 도출해내는 구조를 가진다. 따라서 이전 state의 정보를 고려할 수 있다는 장점이 있지만 입, 출력의 길이가 상이할 경우에는 적용하기 어렵다는 한계가 있기 때문이다.
\begin{matrix}
h_t=\sigma(\mathbf{W}^{hx}x_t+\mathbf{W}^{hh}h_{t-1})
\end{matrix}
\begin{matrix}
y_t=\mathbf{W}^{yh}h_t
\end{matrix}
이제 2014년도에 작성된 논문’Sequence to Sequence Learning with Neural Networks‘에서 시행한 실험에 대해 간단히 언급하도록 하겠다.
- Differences from the models described above: three important ways
1. Sequence to Sequence Learning with Neural Networks논문에서 진행된 실험에서는 RNN cell에 LSTM을 적용하였으며 input sequence와 output sequence에 대해 다른 LSTM을 사용하였다. 즉 두개의 다른 LSTM을 사용하여 Encoder와 Decoder의 네트워크를 분리시켰다. 왜냐하면 모델의 파라미터 수가 늘어나며 더 많은 양의 학습이 가능하기 때문이다.
2. 또한 위 그림(1)에서도 알 수 있듯이 seq2seq에서는 일반적으로 layer를 깊게 쌓은 모델을 사용하는데 이 논문에서는 4개의 layer를 사용하였다.
3. 그리고 마지막으로 중요한 특이 사항은 input sequence의 순서를 거꾸로 입력했다는 것이다. 예를 들어 a, b, c가 입력되어 $\alpha$,$\beta$,$\gamma$값을 예측하는 작업에서 입력 순서를 뒤집어 c, b, a를 입력한 것인데 이러한 작업을 통해 모델의 성능이 높아지는 결과를 얻었다. 이를 통해 모델의 성능이 높아졌는데 그 이유는 이러한 data transformation을 통해 데이터에 변형을 주기 전보다 a가 예측해야 하는 $\alpha$와, b가 예측해야 하는 $\beta$와 가까워져 SGD(Stochastic Gradient Descent)를 위한 input과 output간의 “상호 교신(“establish communication)”이 수월해졌기 때문이다.(data transformation은 학습할 때만 적용했다.)
- Dataset details: 160,000 input vocabulary, 80,000 output vocabulary
해당 논문에서는 위 모델을 WMT’14 English to French MT(machine translation) task에 적용하였다. 이 실험을 위해 WMT’14 English to French dataset의 12M문장 중 348M 프랑스 단어와 304M의 영어 단어 데이터가 사용되었다. 그리고 각 단어들을 벡터로 표현하기 위해 두 언어에 대해 각각 고정된 vocabulary를 사용했는데 여기에는 source language에서 가장 빈번히 사용되는 160,000개의 단어와 target language에서 빈번히 사용되는 80,000개의 단어가 포함되어 있다. 그리고 out-of-vocabulary에 대해서는 “$UNK$”라는 token을 부여하도록 했다.
- Decoding and Rescoring: 1000 cell at each layer, 1000dimensional word embeddings
이 실험의 핵심은 많은 문장 쌍들에 대해 깊은 LSTM을 사용했다는 것이다. 해당 모델의 학습은 source sentence $S$가 정확히 번역된 target sentence $T$(정답 값이라 생각하면 된다)의 $log$ 확률 값을 최대화하는 과정이다. 따라서 학습에 대한 수식은 다음과 같다:
\begin{matrix}
1/\vert S\vert\sum_{(T,S)\in S}\log p(T\vert S)
\end{matrix}
위 수식에서 $S$는 training set이다. 이와 같은 학습이 완료된 후에는 LSTM에 의해 가장 비슷하게 번역된 것을 찾는 작업을 하는데 해당 작업에 대한 수식은 다음과 같다:
\begin{matrix}
\hat{T}=\arg\max_T p(T\vert S)
\end{matrix}
해당 논문에서는 simple left-to-right beam search방식을 decoder에서 사용하였다. 즉, 가정할 단어 수를 B개라고 가정한 후(후보 단어의 수를 B개로 설정한 후) time-step마다 vocabulary에 존재하는 가능한 각각 다른 단어들을 추가하여 이들 중 모델의 $log$확률값이 가장 높은 B개를 제외한 후 나머지는 모두 버린다. (본 논문에서는 1000개의 best-list를 사용하였고 모델은 위에서도 언급했듯이 LSTM을 사용하였다.)그리고 $EOS$ token이 나오면 문장에 이를 추가한 후 완성된 문장을 만든다.
- Reversing the Source Sentence: data transformation
앞서 언급했 듯이 source sentence를 뒤집어 입력했을 때 더 좋은 성능을 보였는데 해당 방법을 통해 perplexity는 5.8에서 4.7로 떨어졌고, BLEU score은 25.9에서 30.6로 오르는 결과를 보였다. 현재 이러한 현상에 대한 구체적인 이유는 알 수 없지만, 데이터에 변형을 주지 않을 경우 source sentence와 target sentence를 concatenate할 때 source sentence에 있는 각 단어들은 target sentence에 있는 관련된 단어와 멀어지게 된다. 이는 minimal time lag문제를 야기시키는데 Source sentence를 뒤집음으로써 서로 관련 있는 source language와 target language의 평균 거리에는 변화가 없지만, 앞쪽 몇몇 단어들의 거리가 굉장히 가까워져 minimal time lag문제가 눈에 띄게 개선된 것을 확인할 수 있었다. 해당 문제가 개선될 수 있었던 이유는 backpropagation할 때 source sentence와 target sentence간의 “상호 교신(establishing communication)”이 수월해졌기 때문이다.
- Result
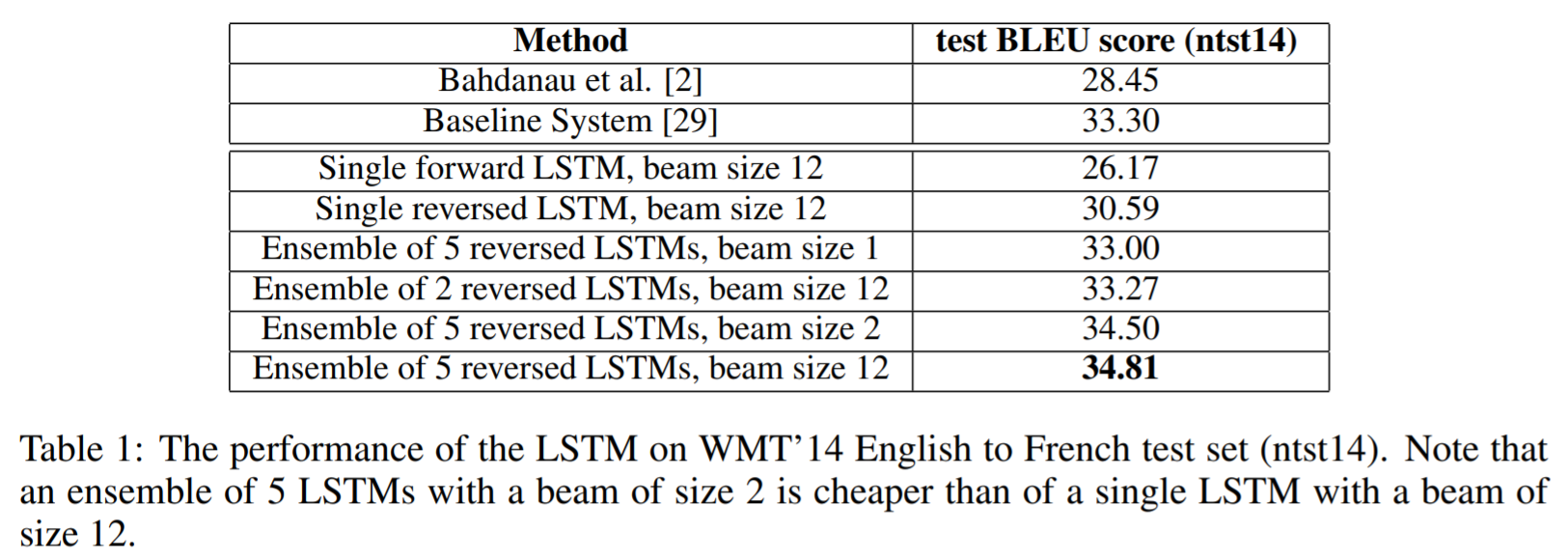

2.3 Model Analysis
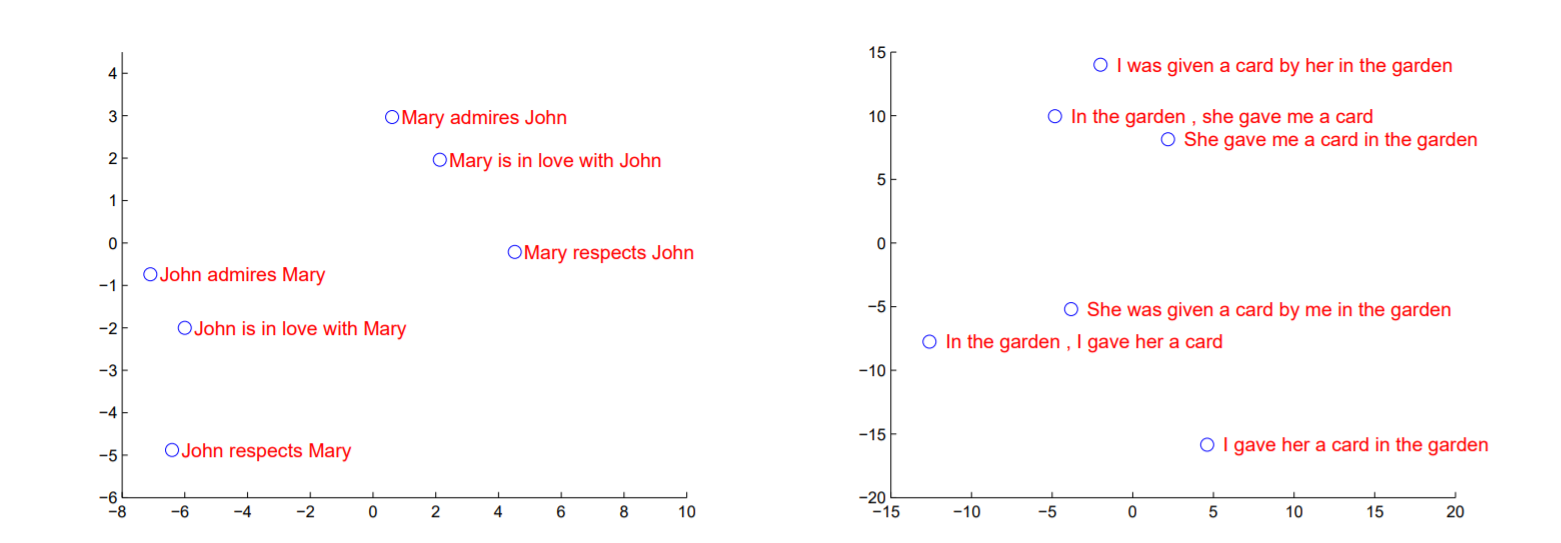
위 그림은 context vector(fixed-length vector)를 PCA를 통해 2차원 공간에 투사한 결과이다. 해당 그림을 보면 문장 순서에 따라 값이 크게 달라지는데 능동과 수동문에 대해서는 값의 차이가 크지 않은 것을 확인할 수 있다.
2.4 Teacher Forcing
추가적으로, 학습 시 활용될 수 있는 Teacher Forcing기법에 대해 설명하도록 하겠다.
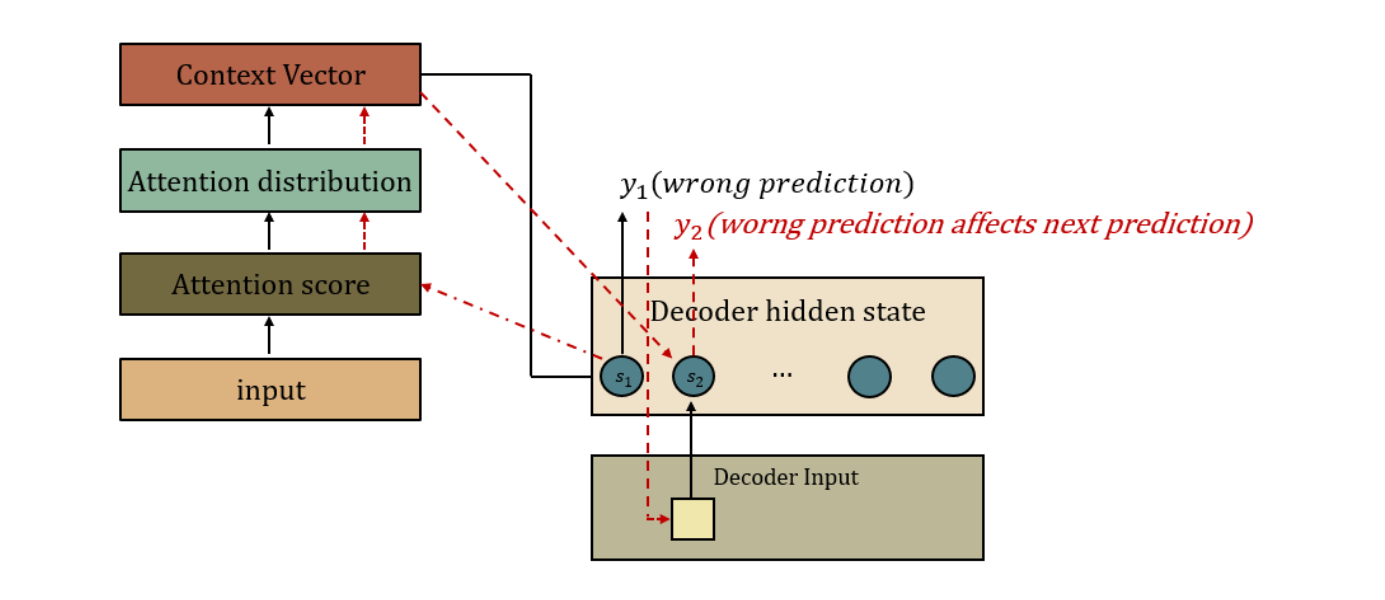
Illustrated by the author
위 그림과 같이 만약 prediction값이 틀렸을 경우에, 틀린 값이 prediction으로 나왔는데 이걸 다시 fully connected에 넣으면 문제가 생긴다. 그렇기 때문에 이런경우를 대비하여 prediction 값 대신 정답을 Decoder의 Input으로 입력하여 이전에 잘못된 결과가 나왔더라도 정답을 그 다음 step의 입력으로 넣으으러써 학습을 더 빠른고 효율적으로 만들어준다:
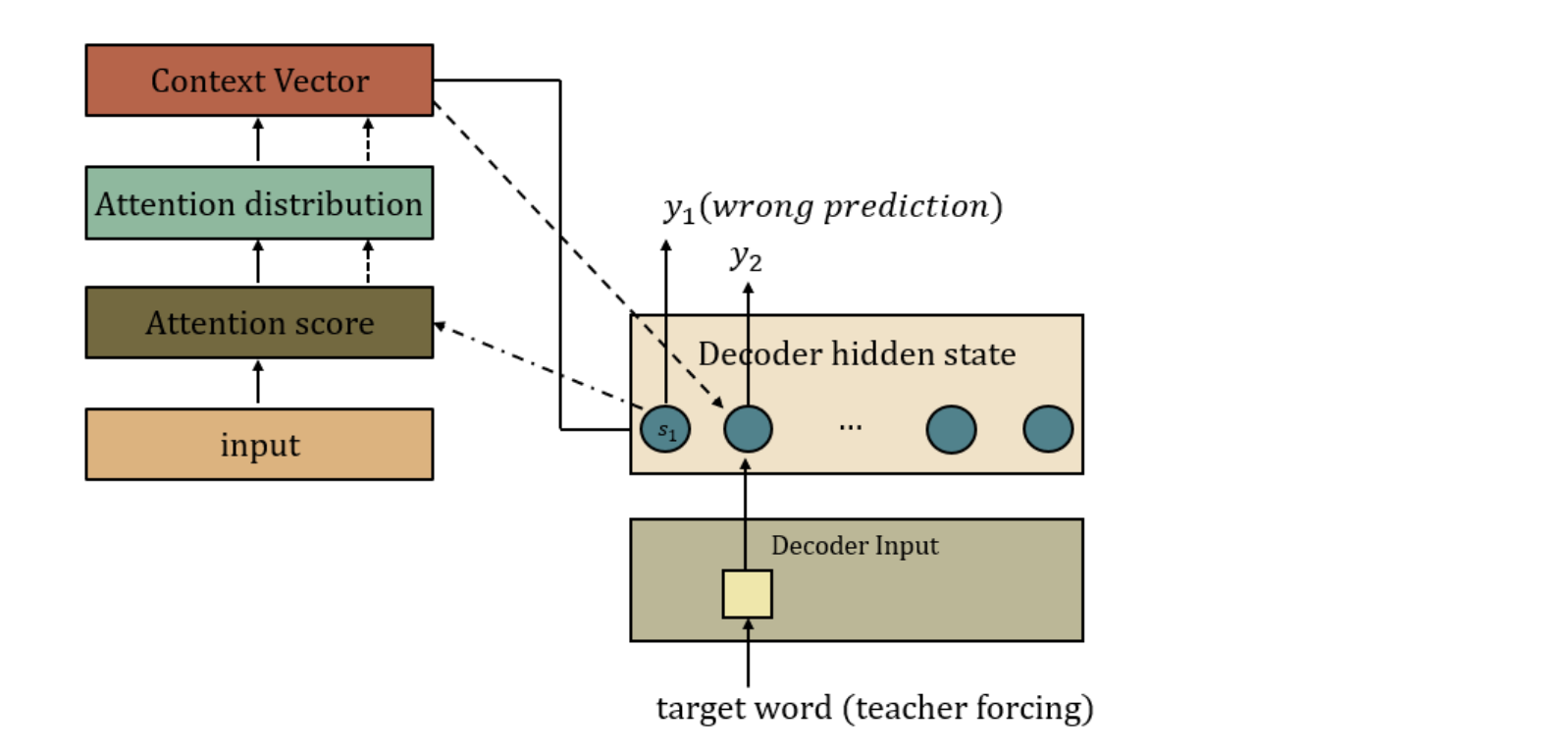
Illustrated by the author
2.5 Applications of seq2seq
지금까지 Seq2seq모델에 대한 설명과 그에 대한 실험을 간략하게 살펴보았다. 본 모델은 기계번역을 포함하여 아래와 같이 다양한 분야에서 사용될 수 있다:
Applications of seq2seq
Tasks
Neural Machine Translation (NMT)
Source language문장을 입력으로 받아 같은 의미의 target language문장을 출력
Chatbot
문장을 입력으로 받아 그에 대한 대답을 출력
Summarization
긴 문장을 입력으로 받아 그를 요약하여 출력
Automatic Speech Recognition (ASR)
말소리를 입력으로 받아 해당 언어를 문자로 변환하여 출력
Image Captioning
이미지를 입력으로 받아 해당 이미지에 대한 설명을 문자로 출력(변형된 seq2seq 사용)
2.6 Limitation
Seq2seq모델의 한계에 대해서도 알아보겠다.
1) Memorization
Neural Network모델은 데이터를 압축시키는 것에 있어 좋은 성능을 자랑한다. 하지만 데이터를 압축시키는 것에도 한계가 있다. 예를 들어 본 글에서 지금까지 나열한 수많은 정보를 단 한 줄로 요약하라면 많은 정보의 손실이 있게 될 것이다. 따라서 문장이 길어질수록 성능이 저하되는데 이러한 문제를 해결하기 위해 고안된 대표적인 Mechanism이 Attention이다.
2) Lack of Structural Information
현재 Deep-learning NLP는 문장을 단순히 sequential data로서 처리하는 경향이 있다. 이러한 상황에서는 sequential data를 처리하는 것에 높은 성능을 보이는 seq2seq모델은 성공적이지만 NLP의 발전을 위해서는 문장을 구조를 체계적으로 이해하는 모델이 필요하다.
3) Conversation
인간과 기계 간의 대화가 가능하기 위해서는 단순한 질문-대답 형식을 구현하는 모델에서 해당 형식의 대화보다 더 많은 대화 형식을 구현할 수 있는 모델이 필요하다(화용론 하위 주제인 CA(conversation analysis)참고). 대화의 경우에는 대화의 흐름에 따라 새로운 정보가 계속 추가된다. 번역이나 요약의 경우 새로운 정보에 대한 고려 없어도 문제가 없지만 chatbot같은 경우에는 더 발전된 architecture가 필요하다.
Reference
Francois Chaubard, Michael Fang, Guillaume Genthial, Rohit Mundra, Richard Socher.”CS224n: Natural Language Processing with Deep Learning: Part1,”(winter 2017)
Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio.”Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,”(2014)
Ilya Sutskever, Oriol Vinyals, Quoc V. Le.”Sequence to Sequence Learning with Neural Networks,”(2014)
CS224D Lecture 8 - 2015 - Fancy Recurrent Neural Networks for Machine Translation
Kim, Ki Hyun.Natural Language Processing with PyTorch.seoul:Hanbit Publishing Network,2019
Seq2Seq 실습 코드: https://finddme.github.io/natural%20language%20processing/2019/11/11/Seq2SeqCode/
- 1.Machine Translation
- 1.1 Why is it so hard?
- 1.2 History
- 2. Sequence to Sequence Model
- 2.1 Architecture of seq2seq model
- 2.2 Experiment
- 2.3 Model Analysis
- 2.4 Teacher Forcing
- 2.5 Applications of seq2seq
- 2.6 Limitation
- Reference
해당 게시물에서 소개할 Seq2Seq모델은 기계번역에 사용되는 것으로 잘 알려져 있다. 따라서 모델 설명 이전에 가볍게 번역 과제에 대해 언급하도록 하겠다.
1.Machine Translation
1.1 Why is it so hard?
번역 과제는 source language의 의미를 target language로 옮겨 다른 두 언어가 같은 의미를 지니게하도록 하는 작업이다. 해당 작업은 여러 자연어처리 과제 중 어려운 과제에 속한다. 아래는 번역 과제가 어려운 이유이다:
1) 인간의 언어는 단순히 합성성의 원리로만 이해될 수 없다. 즉 의미를 지닌 단어들을 쭉 나열한다고 해서 나열된 단어들의 전체 의미가 각 단어들의 의미의 합과 같지 않다는 것이다. 대표적으로 관용구를 예로 들 수 있다.
2) 함축을 활용하여 다양한 정보를 전달한다.
-
인간은 말해진 것 이상의 의미(대화에서 내포하고있는 의미)를 주고 받는다. 이를 해석하기 위해서는 협력원리가 작용한다. 협력의 원리에는 양, 질, 관계, 태도 이렇게 네 가지의 대화의 격률이 존재하는데 대화과정에서 대화격률이 의도적으로 위반되는 경우에도 협력원리가 유지된다는 가정하에 화자는 특정한 의미를 함축하게 된다. 또한 청자도 화자의 발화로부터 전달되는 문자적 의미와 배경지식 등을 고려하여 화자의 함축된 의미를 추론함으로써 의사소통을 한다.
-
자연어의 표현은 의미가 고정되지 않고 대화 문맥에 따라 의미가 달라진다.
-
항진명제와 은유가 빈번히 사용된다.
3) 특히 한국어 같은 경우 생략 현상과 강세 변화에 따른 의미 변화가 다른 언어에 비해 더 많이 나타난다.
1.2 History
이어서 기계번역의 역사에 대해서도 짚어보고 가겠다.
1) RBMT(Rule-Based Machine Translation)
: 전통적인 번역 방식인 규칙 기반 기계번역이다. 말 그대로 형태, 통사, 의미 정보가 포함된 광범위한 어휘소와 대규모 규칙을 필요로 하는 번역 방식이다. 해당 규칙은 사람이 만들어야 하기 때문에 많은 자원과 시간이 소모된다. 또한 언어는 매일매일 지속적으로 변화한하기에 번역 언어쌍 확장은 필수적으로 이루어져야 하는데 이때 번역 품질 향상을 위해 전문가가 매번 새로운 규칙을 찾아내 적용해야한다. 따라서 지속적이 투자가 필요하기 때문에 실제 산업에서는 사용률이 저조했다.
2) SMT(Statistical Machine Translation)
: 통계 기반 기계번역으로 대량의 양방향 코퍼스에서 통계를 얻어내 번역 시스템을 구성한다. 언어쌍 업로드가 RBMT에 비해 비교적 빠르고 간단하다.
3) NMT(Neural Machine Translation) :
딥러닝 기반의 기계번역. 해당 방식의 도입으로 인해 기계번역 발전에 박차를 가할 수 있었다. 이전까지 연구된 기계번역 방식보다 NMT가 잘 작동하는 이유는 다음과 같다:
-
End-to-end Model $\rightarrow$ SMT의 경우 여러가지 모듈로 구성되어 시스템이 복잡해 훈련에 어려움이 있었던 반면, NMT는 단 하나의 모델을 사용함으로써(전체를 하나의 모델로 한번에 학습함으로써) 시스템을 단순화 하여 성능을 높였다.
-
Better language model $\rightarrow$ 신경망 언어모델(Neural Network Language Model)을 기반으로 하는 구조이기에 기존의 SMT에서 사용하던 n-gram 방식의 언어 모델보다 강력하다. 희소성(sparseness)문제가 해결 되었으며, 자연스러운 번역을 가능하게 한다. (간단히 말하자면 모델 자체가 더 나아졌다는 것이다.)
-
Great context embedding $\rightarrow$ Neural Network모델은 데이터를 압축시키는 것에 있어 좋은 성능을 자랑한다. 따라서 문장의 의미를 벡터화(vectorize)하는 능력이 뛰어납니다. 따라서, 노이즈나 희소성(sparseness)문제를 이전보다 잘 해결할 수 있다.(간단히 말하자면 임베딩 기능이 향상되었다는 것이다.)
2. Sequence to Sequence Model
이제 본격적으로 Seq2Seq이라는 모델에 대해 소개하도록 하겠다. 일반적인 Deep Neural Network같은 경우 다양한 분야에서 좋은 성과를 보였으나 sequence data처리에는 큰 성과를 보이지 못 했다. 이는 input dimension과 output dimension이 고정되어 있기 때문이다. 물론 convolution연산의 경우 input의 크기가 정해져 있지 않지만 Multi-Layer-Perceptron의 경우에는 입력의 차원과 출력의 차원을 정한 후에 학습을 시작한다. 이러한 방식은 이미지 데이터와 같이 크기가 고정된 데이터를 처리할 경우에 유용하게 사용될 수 있다. 하지만 인간이 주고받는 언어의 입력과 출력 크기는 상황에 따라, 사람에 따라 매우 상이하다. 따라서 위에서 언급된 모델들로는 인간의 언어를 학습시키는 것에 어려움이 있다. 이러한 문제점을 해결하기 위해 고안된 모델이 오늘 설명할 seq2seq모델이다.
위에서 언급한 바와 같이 seq2seq은 입, 출력의 크기가 정해지지 않아도 학습이 가능한 모델이다. 이는 모델의 구조를 살펴보면 그것이 가능한 이유를 알 수 있다. seq2seq 구조는 크게 Encoder와 Decoder로 나뉜다. Encoder는 입력문장을 받아 그것을 벡터로 변환하는 역할을 하고, Decoder의 경우에는 Encoder를 통해 만들어진 벡터를 사용하여 다시 또 다른 문장을 만들어 내는 것이다. Decoder 부분에서 Generator라는 모듈을 따로 떨어트려 살펴보면 이는 Decoder의 출력 벡터들을 Softmax를 통과시켜 가장 높은 확률을 가진 단어 하나를 추출해 내는 작업이 이루어지는 곳이다. Seq2seq모델을 수식화 하면 다음과 같이 표현할 수 있다:
\begin{matrix} {\theta}^{ * } \approx argmax \ P(Y|X ;\theta) \ where\ X=\ { x_1, x_2, x_3, …, x_n\ } , Y=\ { y_1, y_2, y_3, …, y_m\ } \end{matrix}
위 수식을 통해 Seq2seq은 모델의 파라미터($\theta$)가 주어졌을 때 source data($X$)를 받아서 target data($Y$)를 가장 높은 확률의 값으로 반환할 때 해당 확률을 최대로 올리는, 즉 $P(Y|X ;\theta)$ 를 최대로 하는 모델 파라미터를 학습하는 모델이라는 것을 나타낸다.
Seq2seq모델은 말 그대로 sequence data가 들어가서 sequence data가 나오는 모델로, 간단히 말하자면 many-to-many방식의 RNN인데 encoder, decoder, generator를 통해 높은 확률의 결과 값을 도출하도록 학습하는 모델이다.
2.1 Architecture of seq2seq model
위 그림을 보며 지금까지 개괄적으로 언급한 내용에 대해 조금 더 자세히 살펴보도록 하겠다.
$\circ$ Encoder
이곳에서는 $P(X)$를 모델링한다. 위 그림을 보면 $x_1$ (I), $x_2$ (love), $x_3$ (you)라는 입력이 순차적으로 입력되며 각각 embedding layer를 거치며 벡터화(vectorize) 되어 Stacked RNN Cell에 들어가는 것을 확인할 수 있다. 여기에서 Stacked RNN Cell은 Multi layer RNN이라고 생각하면 된다. 이곳에는 Vanilla RNN, LSTM, GRU, Bidirectional-RNN과 같은 RNN계열의 모델들이 사용될 수 있다(논문 Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation에서는 GRU를, Sequence to Sequence Learning with Neural Networks에서는 LSTM을 활용하였다). 각 입력에 대한 hidden state값들은 일반적인 RNN계열 모델들과 같이 다음 state로 넘어가서 해당 state의 input 값과 함께 입력된다. 그렇게 Encoder의 마지막 입력 값이 들어오면 padding 작업 후 Encoder부분의 마지막 hidden state값을 context vector(fixed-length vector)로 활용하여 Decoder로 넘긴다. 따라서 context vector는 Encoder정보를 함축하여 담고 있는 vector이다. Encoder를 수식으로 표현하면 다음과 같다.
\begin{matrix} { h }_ { t }^{ src }={ RNN }_ { enc }({ emb }_ { src } (x_t), { h }_ { t-1 }^{ src }) \end{matrix}
\begin{matrix} {H}^{ src }= [h_1^{src}; {h}_ {2}^{ src }; \dots ; {h}_ {n}^{ src }] \end{matrix}
위 수식은 time-step별로 RNNcell을 통과시킨 것을 나타낸다. ${ h }_{ t }^{ src }$는 $t$번째 source state의 hidden vector값을 뜻한다. 이는 Encoder부분의 RNN cell을 지나는데 해당 RNN cell에는 source data인 $x_t$의 embedding 값과 이전 hidden vector가 들어간다. 이렇게 나온 각 state의 hidden vector값은 모두 concatenate되어 ${ H }^{ src }$가 도출된다. 이는 사실상 코딩을 할 경우 아래와 같은 수식이 된다.
\begin{matrix} {H}^{src}= {RNN}_ {enc}({emb}_ {src}(X),{ h }_ { 0 }^{src}) \end{matrix}
$\circ$ Decoder
Decoder부분의 경우 문장의 시작을 알리는 $BOS$(begin-of-sentence)token과 끝을 알리는 $EOS$(end-of-sentence)token이 존재한다. Decoder의 시작부분 같은 경우에는 context vector와 임의의 초기값으로 설정한 $y$(이전 state의 출력 값)와 $s$(이전 state의 hidden vector값)가 입력되어 첫 출력 값을 도출한다. 이후에는 context vector와 이전 state의 출력 값으로 나온 $y$ 즉, ${y}_{i-1}$와 이전 state의 hidden vector인 $s$ 즉, ${s}_{i-1}$이 Encoder에서와 같이 RNN계열의 모델에 입력된다. 여기에서 context vector는 항상 같은 값이 사용된다.
seq2seq모델의 진행 방식을 time-step에 대해 수식화 하자면 다음과 같다.
\begin{matrix} {P}_ { \theta }(Y│X)=\prod_{t=1}^{m} {P}_ { \theta }(y_t |X, y_{<t}) \end{matrix}
\begin{matrix} \log P_{ \theta }(Y|X)=\sum_{t=1}^{m} \log P_{ \theta }(y_t|X, y_{<t}) \end{matrix}
위 수식은 이전 time-step의 결과와 encoder로부터 도출된 결과($X$)를 기반으로 하여 target값($Y$)을 유추해내는 작업을 표현하고 있다.
아래 수식은 Decoder부분을 수식으로 표현한 것이다.
\begin{matrix} { h }_ { t }^{ tgt }={ RNN }_ { dec } ({ emb }_ { tgt }({ y }_ { t-1 }), { h }_ { t-1 }^{ tgt }) \ where \ { h }_ { 0 }^{ tgt } = { h }_ { n }^{ src } \ and \ y_0=BOS \end{matrix}
위 수식을 살펴보면 ${ h }_{ t }^{ tgt }$ 는 $t$번째 target state의 hidden vector인데 이는 Decoder부분의 RNN cell에 이전 state의 결과 값($y_{t-1}$)을 embedding한 값과 이전 state에서 나온 hidden vector값이 입력되어 도출된다. 여기에서 주의 깊게 살펴볼 점은 decoder부분의 첫 시작에서는 $y$의 초기 값으로써 $BOS$를 입력한다는 것이다.
$\circ$ Generator
Generator부분에서는 Decoder부분의 RNN Cell을 거쳐 나온 값들이 softmax를 거쳐 0부터 1사이의 확률 값으로 변환되어 가장 높은 확률 값이 해당 state의 출력 값으로 도출된다. 아래는 Generator 부분을 수식화 한 것이다.
\begin{matrix} \hat{ y }_ { t }=softmax({ linear }_ { hs\rightarrow \left\vert { V }_ { tgt } \right\vert }({ h }_ { t }^{ tgt })) \ and \ \hat{ y }_ { m }=EOS \end{matrix}
위 수식에서 softmax는 비선형 함수임에도 그 속에 선형 함수가 들어있는 것을 볼 수 있다. 이는 decoder에서 도출된 각 state의 hidden vector값들을 0-1사이의 확률 값으로 변환하기 위해 차원을 늘려주는 작업이다. 그리고 여기에서 특기할 점은 decoder부분의 첫 입력 값으로 계산의 시작을 나타내는 초기값 $BOS$가 있듯이 decoder 계산의 종료를 알리는 $EOS$ token이 존재한다는 것이다.
2.2 Experiment
지금까지 seq2seq모델의 구조를 하나하나 뜯어 살펴보았는데 위와 같은 방식은 특히 긴 문장을 처리할 때 일반적인 RNN계열의 모델만 단순히 사용했을 보다 더 좋은 성능을 보이게 된다. 왜냐하면 RNN은 일반적인 feedforward neural network인데 즉, input($x_1$, $x_2$, $x_3$ $\dots$ $x_n$)에 대해 아래 수식을 반복하며 output($y_1$, $y_2$, $y_3$ $\dots$ $y_T$)을 도출해내는 구조를 가진다. 따라서 이전 state의 정보를 고려할 수 있다는 장점이 있지만 입, 출력의 길이가 상이할 경우에는 적용하기 어렵다는 한계가 있기 때문이다.
\begin{matrix} h_t=\sigma(\mathbf{W}^{hx}x_t+\mathbf{W}^{hh}h_{t-1}) \end{matrix}
\begin{matrix} y_t=\mathbf{W}^{yh}h_t \end{matrix}
이제 2014년도에 작성된 논문’Sequence to Sequence Learning with Neural Networks‘에서 시행한 실험에 대해 간단히 언급하도록 하겠다.
- Differences from the models described above: three important ways
1. Sequence to Sequence Learning with Neural Networks논문에서 진행된 실험에서는 RNN cell에 LSTM을 적용하였으며 input sequence와 output sequence에 대해 다른 LSTM을 사용하였다. 즉 두개의 다른 LSTM을 사용하여 Encoder와 Decoder의 네트워크를 분리시켰다. 왜냐하면 모델의 파라미터 수가 늘어나며 더 많은 양의 학습이 가능하기 때문이다.
2. 또한 위 그림(1)에서도 알 수 있듯이 seq2seq에서는 일반적으로 layer를 깊게 쌓은 모델을 사용하는데 이 논문에서는 4개의 layer를 사용하였다.
3. 그리고 마지막으로 중요한 특이 사항은 input sequence의 순서를 거꾸로 입력했다는 것이다. 예를 들어 a, b, c가 입력되어 $\alpha$,$\beta$,$\gamma$값을 예측하는 작업에서 입력 순서를 뒤집어 c, b, a를 입력한 것인데 이러한 작업을 통해 모델의 성능이 높아지는 결과를 얻었다. 이를 통해 모델의 성능이 높아졌는데 그 이유는 이러한 data transformation을 통해 데이터에 변형을 주기 전보다 a가 예측해야 하는 $\alpha$와, b가 예측해야 하는 $\beta$와 가까워져 SGD(Stochastic Gradient Descent)를 위한 input과 output간의 “상호 교신(“establish communication)”이 수월해졌기 때문이다.(data transformation은 학습할 때만 적용했다.)
- Dataset details: 160,000 input vocabulary, 80,000 output vocabulary
해당 논문에서는 위 모델을 WMT’14 English to French MT(machine translation) task에 적용하였다. 이 실험을 위해 WMT’14 English to French dataset의 12M문장 중 348M 프랑스 단어와 304M의 영어 단어 데이터가 사용되었다. 그리고 각 단어들을 벡터로 표현하기 위해 두 언어에 대해 각각 고정된 vocabulary를 사용했는데 여기에는 source language에서 가장 빈번히 사용되는 160,000개의 단어와 target language에서 빈번히 사용되는 80,000개의 단어가 포함되어 있다. 그리고 out-of-vocabulary에 대해서는 “$UNK$”라는 token을 부여하도록 했다.
- Decoding and Rescoring: 1000 cell at each layer, 1000dimensional word embeddings
이 실험의 핵심은 많은 문장 쌍들에 대해 깊은 LSTM을 사용했다는 것이다. 해당 모델의 학습은 source sentence $S$가 정확히 번역된 target sentence $T$(정답 값이라 생각하면 된다)의 $log$ 확률 값을 최대화하는 과정이다. 따라서 학습에 대한 수식은 다음과 같다:
\begin{matrix} 1/\vert S\vert\sum_{(T,S)\in S}\log p(T\vert S) \end{matrix}
위 수식에서 $S$는 training set이다. 이와 같은 학습이 완료된 후에는 LSTM에 의해 가장 비슷하게 번역된 것을 찾는 작업을 하는데 해당 작업에 대한 수식은 다음과 같다:
\begin{matrix} \hat{T}=\arg\max_T p(T\vert S) \end{matrix}
해당 논문에서는 simple left-to-right beam search방식을 decoder에서 사용하였다. 즉, 가정할 단어 수를 B개라고 가정한 후(후보 단어의 수를 B개로 설정한 후) time-step마다 vocabulary에 존재하는 가능한 각각 다른 단어들을 추가하여 이들 중 모델의 $log$확률값이 가장 높은 B개를 제외한 후 나머지는 모두 버린다. (본 논문에서는 1000개의 best-list를 사용하였고 모델은 위에서도 언급했듯이 LSTM을 사용하였다.)그리고 $EOS$ token이 나오면 문장에 이를 추가한 후 완성된 문장을 만든다.
- Reversing the Source Sentence: data transformation
앞서 언급했 듯이 source sentence를 뒤집어 입력했을 때 더 좋은 성능을 보였는데 해당 방법을 통해 perplexity는 5.8에서 4.7로 떨어졌고, BLEU score은 25.9에서 30.6로 오르는 결과를 보였다. 현재 이러한 현상에 대한 구체적인 이유는 알 수 없지만, 데이터에 변형을 주지 않을 경우 source sentence와 target sentence를 concatenate할 때 source sentence에 있는 각 단어들은 target sentence에 있는 관련된 단어와 멀어지게 된다. 이는 minimal time lag문제를 야기시키는데 Source sentence를 뒤집음으로써 서로 관련 있는 source language와 target language의 평균 거리에는 변화가 없지만, 앞쪽 몇몇 단어들의 거리가 굉장히 가까워져 minimal time lag문제가 눈에 띄게 개선된 것을 확인할 수 있었다. 해당 문제가 개선될 수 있었던 이유는 backpropagation할 때 source sentence와 target sentence간의 “상호 교신(establishing communication)”이 수월해졌기 때문이다.
- Result
2.3 Model Analysis
위 그림은 context vector(fixed-length vector)를 PCA를 통해 2차원 공간에 투사한 결과이다. 해당 그림을 보면 문장 순서에 따라 값이 크게 달라지는데 능동과 수동문에 대해서는 값의 차이가 크지 않은 것을 확인할 수 있다.
2.4 Teacher Forcing
추가적으로, 학습 시 활용될 수 있는 Teacher Forcing기법에 대해 설명하도록 하겠다.
위 그림과 같이 만약 prediction값이 틀렸을 경우에, 틀린 값이 prediction으로 나왔는데 이걸 다시 fully connected에 넣으면 문제가 생긴다. 그렇기 때문에 이런경우를 대비하여 prediction 값 대신 정답을 Decoder의 Input으로 입력하여 이전에 잘못된 결과가 나왔더라도 정답을 그 다음 step의 입력으로 넣으으러써 학습을 더 빠른고 효율적으로 만들어준다:
2.5 Applications of seq2seq
지금까지 Seq2seq모델에 대한 설명과 그에 대한 실험을 간략하게 살펴보았다. 본 모델은 기계번역을 포함하여 아래와 같이 다양한 분야에서 사용될 수 있다:
| Applications of seq2seq | Tasks |
|---|---|
| Neural Machine Translation (NMT) | Source language문장을 입력으로 받아 같은 의미의 target language문장을 출력 |
| Chatbot | 문장을 입력으로 받아 그에 대한 대답을 출력 |
| Summarization | 긴 문장을 입력으로 받아 그를 요약하여 출력 |
| Automatic Speech Recognition (ASR) | 말소리를 입력으로 받아 해당 언어를 문자로 변환하여 출력 |
| Image Captioning | 이미지를 입력으로 받아 해당 이미지에 대한 설명을 문자로 출력(변형된 seq2seq 사용) |
2.6 Limitation
Seq2seq모델의 한계에 대해서도 알아보겠다.
1) Memorization
Neural Network모델은 데이터를 압축시키는 것에 있어 좋은 성능을 자랑한다. 하지만 데이터를 압축시키는 것에도 한계가 있다. 예를 들어 본 글에서 지금까지 나열한 수많은 정보를 단 한 줄로 요약하라면 많은 정보의 손실이 있게 될 것이다. 따라서 문장이 길어질수록 성능이 저하되는데 이러한 문제를 해결하기 위해 고안된 대표적인 Mechanism이 Attention이다.
2) Lack of Structural Information
현재 Deep-learning NLP는 문장을 단순히 sequential data로서 처리하는 경향이 있다. 이러한 상황에서는 sequential data를 처리하는 것에 높은 성능을 보이는 seq2seq모델은 성공적이지만 NLP의 발전을 위해서는 문장을 구조를 체계적으로 이해하는 모델이 필요하다.
3) Conversation
인간과 기계 간의 대화가 가능하기 위해서는 단순한 질문-대답 형식을 구현하는 모델에서 해당 형식의 대화보다 더 많은 대화 형식을 구현할 수 있는 모델이 필요하다(화용론 하위 주제인 CA(conversation analysis)참고). 대화의 경우에는 대화의 흐름에 따라 새로운 정보가 계속 추가된다. 번역이나 요약의 경우 새로운 정보에 대한 고려 없어도 문제가 없지만 chatbot같은 경우에는 더 발전된 architecture가 필요하다.
Reference
Francois Chaubard, Michael Fang, Guillaume Genthial, Rohit Mundra, Richard Socher.”CS224n: Natural Language Processing with Deep Learning: Part1,”(winter 2017)
Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio.”Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,”(2014)
Ilya Sutskever, Oriol Vinyals, Quoc V. Le.”Sequence to Sequence Learning with Neural Networks,”(2014)
CS224D Lecture 8 - 2015 - Fancy Recurrent Neural Networks for Machine Translation
Kim, Ki Hyun.Natural Language Processing with PyTorch.seoul:Hanbit Publishing Network,2019